[2주차 (1)] 피쳐 엔지니어링 - 1
1. Pandas Group By Aggregation 을 이용한 Feature Engineering
- Feature Engineering 정의 : Feature Engineering은 원본 데이터로부터 도메인 지식 등을 바탕으로 문제를 해결하는데 도움이 되는 Feature을 생성, 변화하고 이를 머신 러닝 모델에 적합한 형식으로 변환하는 작업
- 딥러닝에 비해 머신러닝은 사람이 직접 feature을 찾아서 엔지니어링을 해 주어야 함 , 작업의 성공을 결정하는 중요한 단계
- Pandas Group By Aggregation 을 이용한 Feature Engineering 기법
-원본 데이터에서 주어진 feature에 고객id 기반으로 Pandas Group By Aggregation 함수를 적용하여 새로운 feature 생성
-좋은 feature인지 아닌지 -> 레이블별로 분포가 확연히 달라야 함!


-total-sum 그래프가 total-mean 그래프에 비하여 레이블이 1일 때와 레이블이 0일 때의 분포가 눈에 띄게 다른 것을 확인할 수 있음
-이는 feature engineering을 수행하기 좋은 feature임을 뜻
-머신러닝은 결국 데이터에서 타겟을 구분할 수 있는 패턴을 인식하는 것이고, 따라서 feature가 타겟 레이블별로 분포가 다르다는 것은 곧 모델이 인식이 쉬워진다는 뜻이다
2. Cross Validation 을 이용한 Out of Fold 예측
- 모델 Training 시 Cross Validation을 적용하여 Out of Fold Validation 성능 측정 및 Test 데이터 예측을 통해 성능 향상

**Cross Validation : 데이터를 여러 개의 폴드로 나누어서 Validation 성능을 측정하는 방법
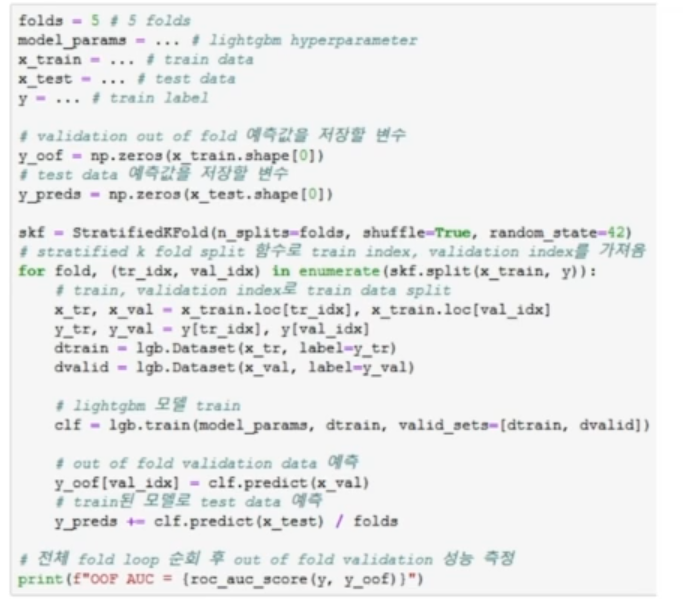
- Out of Fold Validation은 폴드마다 트레이닝한 모델로 테스트 데이터를 예측하고 폴드 갯수 만큼의 테스트 결과값이 도출되면, 이를 average 앙상블에서 최종 테스트 예측 값으로 사용하는 방법을 말한다.
3. LightGBM Early Stopping 적용하여 성능 향상
- Early Stopping : Iteration을 통해 반복 학습이 가능한 머신러닝 모델에서 validation 성능 측정을 통해 validation 성능이 가장 좋은 하이퍼 파라미터에서 학습을 조기 종료하는 정규화 방법이다
- LightGBM Early Stopping : LightGBM에서 몇 개의 트리를 만들 것인지 n_estimators란 하이퍼파라미터로 설정하고 이 개수만큼 트리를 만들지만, 설정한 트리 개수가 최적의 값이라고 볼 수 없음
:Early Stopping은 validation 데이터가 있을 때 LightGBM 트리 개수인 n_estimators는 충분히 크게 설정하고, early_stopping_rounds 값 이상 연속으로 성능이 좋아지지 않으면 더이상 트리를 만들지 않고 가장 validation 성능이 좋은 트리 개수를 최종 트리 개수로 사용

4. Pandas Group by 누적합을 이용한 Feature Engineering

-원본 데이터에서 주어진 Feature 에 고객 ID, 상품 ID, 주문 ID 기반으로 Pandas Group By 누적합 (cumsum) 함수를 적용하여 새로운 Feature 생성
5. 주문, 상품 데이터를 활용한 Feature Engineering

-nunique() 함수를 활용하여 Feature 생성, 고유한 값이 몇 개나 있느냐를 셀 수 있는 함수
6. Time Series 특성을 이용한 Feature Engineering

-month, year_month 함수를 이용하여 Feature을 생성하는 방법
- date type feature의 경우 pandas의 date 라이브러리를 통해 특정 값을 뽑아낼 수 있음
** pandas는 mode() (최빈값 함수)를 지원하지 않음, 따라서 람다 함수 정의해서 사용한다

-Time-Series diff 피쳐 생성하기 : min, max 등의 aggregation function을 사용하면 피쳐 생성 가능
*** Feature 엔지니어링은 필요에 따라, 데이터에 따라 무궁무진한 방법으로 가능, 여러 Feature 엔지니어링 기법을 보며 익히고 이를 적용할 수 있는 능력을 기르는 것이 필요하다
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.