[6주차 (4)] 최적화 - 2
1. Regularization
-Generalization이 잘 되도록 학습의 이점이 최대일 때 학습을 방해해서 학습을 멈추도록 하는 기법
-(1) Early Stopping
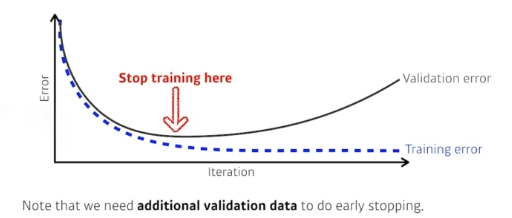
-training 에 활용되지 않은 데이터셋을 validation 데이터로 활용해서 모델성능을 평가하고 loss가 커지는 시점에 train을멈추는 방식
-이를 재평가하기 위해서는 새로운 validation set이 필요
-(2) Parameter Norm Penalty :NN 파라미터가 너무 커지지 않도록 함

:이왕이면 네트워크가 학습할 때 작으면 작을 수록 좋음
:물리적인 의미는 function space 속에서 최대한 부드러운 함수로 -> 부드러운 함수일 수록 generalization performance가 좋을 것이다라고 가정
-(3) Data Augmentation : 데이터가 무한히 많으면 어지간하면 잘 됨
:데이터가 머신 러닝에서 제일 중요함

:데이터가 너무 많아지고 커지면, ML이 기존에 사용하던 방법론들은이 많은 양의 데이터를 표현할 수 있는 표현력과 리소스가 부족해지게 됨, 그러나 현대의 NN은 그럴 능력이 됨
: 문제는 우리에게 선제로 주어진 데이터가 너무나도 한정적이라는 것
:따라서 기존의 데이터를 활용하여 데이터를 더 많은 양으로 증강시킴
: 데이터의 레이블이 유지가 되는 적정선 내에서 augmentation을 진행하는 것이 좋음
-ex) 숫자 반전시키면 레이블이 달라짐
-(4) Noise Robustness

: 왜 잘되는 지에 대해서는 아직까지도 의문
:입력데이터에 노이즈를 삽입하고, 입력데이터 뿐만 아니라, 가중치(weight)에도 노이즈 삽입
:매번 가중치에 노이즈를 삽입하고 흔들어주면 test 단계에서 성능이 좋아진다 연구 결과
-(5) Label Smoothing

: Data Augmentation과 비슷, 차이점이 있다면 데이터 두 개를 뽑아서 두 개를 섞어줌
:효과 = decision boundary를 부드럽게 만들어주는 효과가 있음
:구현하는 코드가 복잡하고 어렵지 않아서, 들인 노력 대비 모델의 성능을 크게 개선할 수 있는 방법 중 하나
-(6) Drop out

: NN의 weight를0으로 바꾸는 작업
: 각각의 neuron들이 조금 뚜렷한 feature을 가질 수 있게 된다
-(7) Batch Normalization
:논란이 많음
:내가 적용하고자하는 레이어의 확률들을 정규화시키는 것
:각각의 레이어가 파라미터의 mean and variance normalization을 진행함 ---> 아 잘 모르겠음
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.