
archive
4. 정렬 (2) - 병합, 퀵 정렬 본문
1. 병합 정렬
-병합 정렬은 일단 입력을 반으로 나누고, 전반부와 후반부를 각각 독립적으로 정렬한다.
-마지막으로 정렬된 두 부분을 합쳐서, 즉 병합하여 정렬된 배열을 얻는다.
-전반부와 후반부를 정렬할 때에도 역시 반으로 나눈 다음 정렬해서 병합한다.
-크기만 절반으로 줄어들었을 뿐 원래의 정렬 문제와 성격이 똑같다는 것을 알 수 있다.
-요약하면, 병합 정렬은 자신에 비해 크기가 반인 문제를 두 개 푼 다음, 이들을 병합하는 작업을 재귀적으로 반복한다.
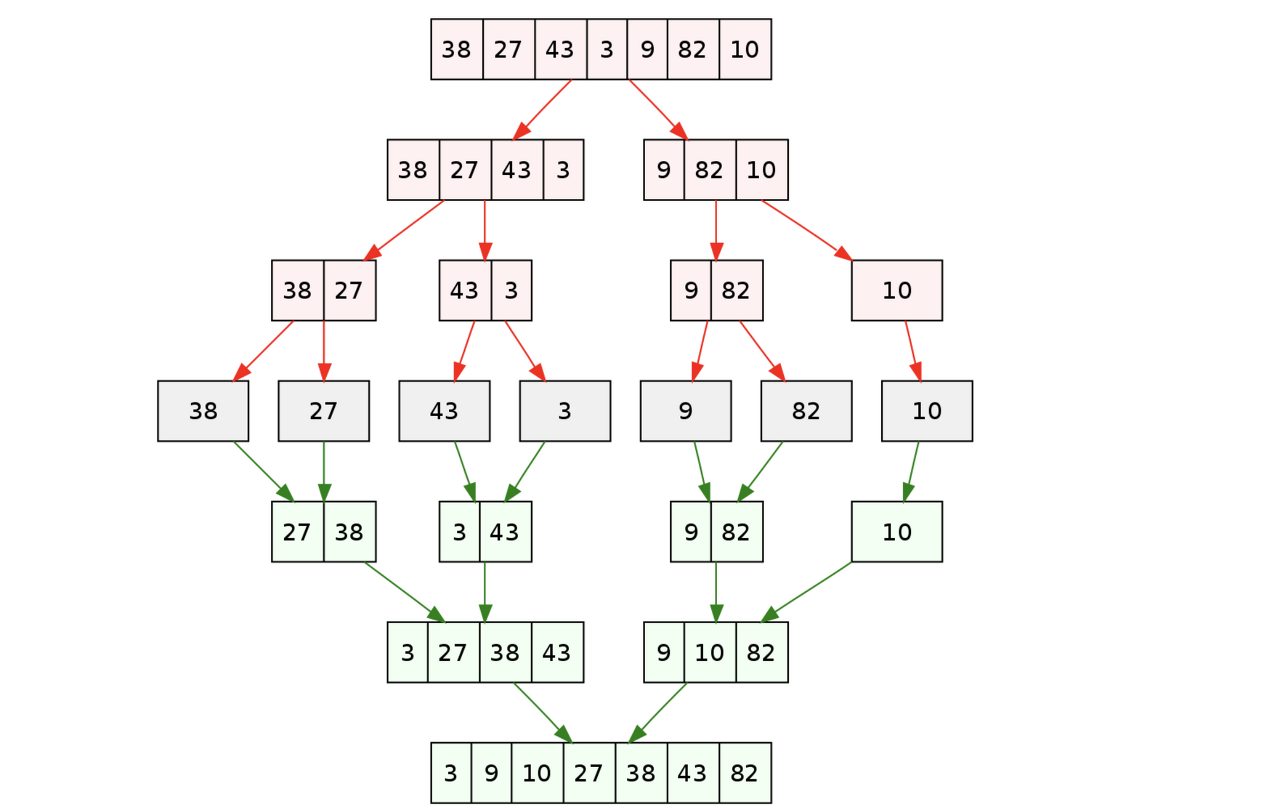
- 이를 코드로 구현하게 되면, tmp[]라는 빈 배열을 하나 형성하고 경쟁을 하여 변수 하나씩 빈 배열에 옮긴다
-병합 정렬의 수행 시간은 최악, 최선, 평균 모든 경우에 O(n log n)이다.
** 스위칭 병합정렬
-이론적으로 보면 병합 정렬은 완벽한 O(n log n)을 보장하는 알고리즘이나, 병합 과정에서 주어진 배열 A[]에 더하여 같은 크기의 보조 배열 tmp[]를 요구한다.
-이 보조 배열 tmp[]는 병합 결과를 임시로 저장한 다음 다시 배열 A[]로 되써준다.
-주어진 배열 이외에 추가로 공간을 사용하지 않는 정렬을 내부정렬이라고 하는데, 병합 정렬은 추가 공간이 필요하므로 내부 정렬이 아니고, 이는 병합 정렬의 가장 큰 단점이다.
-즉, 보조 배열 tmp[]로 병합하였다가 배열 A[]로 되써주는 과정에서 시간 낭비가 발생하게 된다는 것이다.
-보조배열로 인해 추가 공간이 필요하다는 점은 피할 수 없으나, 배열 tmp[]로 병합하였다가 A[]로 되써주는 과정은 개선이 가능하다
-즉, 두 배열이 주 배열과 보조 배열의 역할을 매번 바꾸면서 요령있게 정렬할 수 있다.
-재귀 호출이 한 단계 들어갈 때마다 A[] 와 tmp[]의 역할이 바뀐다
-점근적인 복잡도의 변경은 없다. 시간복잡도는 O(n log n)으로 동일하나 배열 되써주기를 없앤 덕분에 수행 시간이 조금 빨라짐, 계수가 2n에서 n으로 바뀌게 된다.
2. 퀵 정렬
- 퀵 정렬(Quick Sort) 은 기준 원소 하나를 잡아 기준 원소보다 작은 원소와 큰 원소 그룹으로 나누어 기준 원소의 좌우로 분할한 다음 각각을 정렬하는 방법이다.
-평균적으로 좋은 성능을 보이며, 현장에서 많이 사용되는 방법이다.
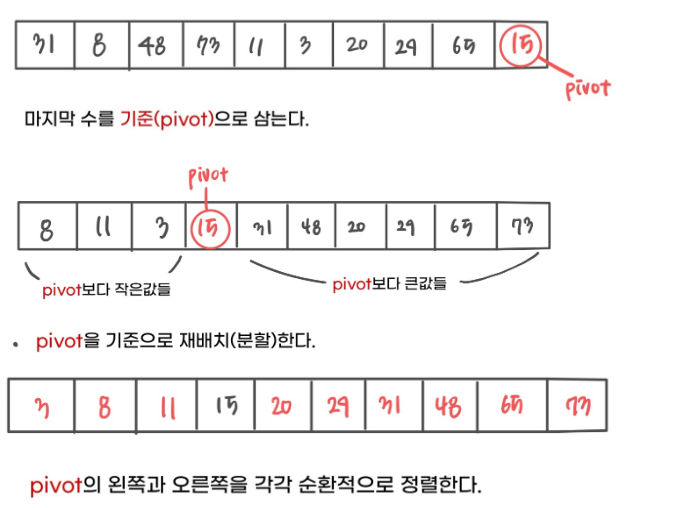
-아무 원소나 기준 원소로 삼아도 상관은 없지만 여기에선 맨 뒤에 있는 원소인 15를 기준 원소로 삼았다.
-왼쪽에는 기준 원소인 15보다 작은 원소, 오른쪽에는 기준 원소보다 큰 원소로 재배치한다
-왼쪽 원소 집합과 오른쪽 원소 집합은 독립적으로 정렬하고 정렬 중엔 기준 원소의 자리는 영향을 받지 않는다, 즉 원소 15는 정렬 전부터 이미 제 자리를 찾은 것이다.
-왼쪽과 오른쪽의 정렬이 끝나는 순간 전체 배열의 정렬이 끝난다.
-왼쪽과 오른쪽을 정렬할 때는 퀵 정렬을 재귀적으로 사용한다.

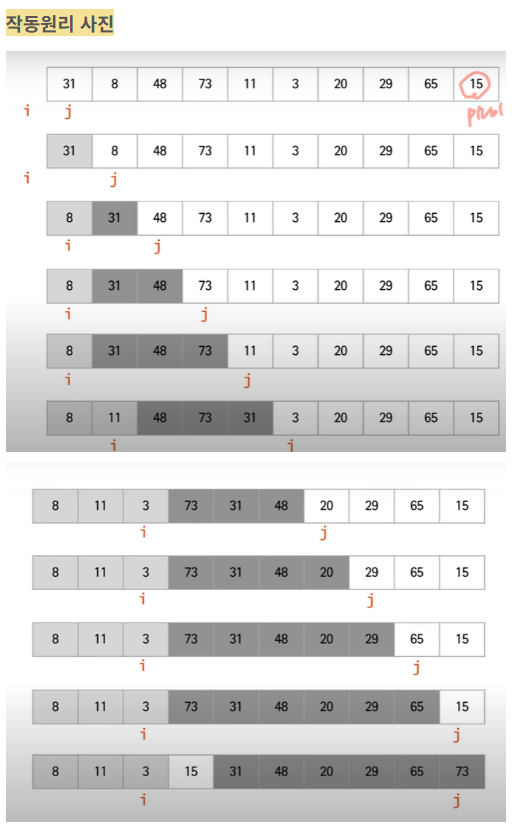
-위 알고리즘에서 발견할 수 있는 몇 가지 성질을 정리하면 다음과 같다
(1) for loop가 한 바퀴 돌 때마다 3구역이 한 칸씩 줄어든다 (아직 연산 전의 원소를 모아둔 구역)
(2) for loop가 한 바퀴 돌 따마다 1구역 (왼쪽) 또는 2구역 (오른쪽) 중 하나가 한 칸 늘어난다.
(3) 2구역이 늘어날 때는 j만 1 증가한다. for loop가 한 바퀴 돌 때마다 자동으로 j는 1 증가하므로 2구역을 늘리기 위해서는 아무 일도 할 필요가 없어진다.
(4) 1구역이 늘어날 때에는 i 와 j가 동시에 1씩 증가한다.
-퀵 정렬의 수행 시간
-우선 분할에 대해서는 왼쪽부터 끝까지 배열을 한 번 훑어나가는 작업이므로 O(n)의 작업시간이 든다.
-퀵 정렬의 수행에서 가장 이상적인 경우는 분할이 항상 반반씩 균등하게 될 때이고, 이 때는 병합 정렬과 같은 모양이 되므로 O(n log n)의 수행시간을 가지게 된다. 평균적인 시간 복잡도도 이와 동일하다.
-최악의 경우는 계속해서 한 쪽은 하나도 없고 다른 쪽에 다 몰리도록 분할이 되는 경우로 시간은 O(n^2)가 된다.
-한 쪽이 완전히 비거나 이에 근접한 상태가 반복되면 위와 같은 비효율적인 시간이 나온다.
-퀵정렬은 실용적으로 매우 빨라 필드에서 가장 선호하는 정렬 알고리즘이다
-최악의 경우 O(n^2)의 시간이 드는 단점은 있지만 이런 일은 거의 발생하지 않는다.
-이와 같은 경우는 두 가지 경우 중 하나이며, 분할이 항상 최악의 경우를 만난다.
(1) 입력이 이미 정렬이 되어있는 경우
(2) 역순으로 정렬이 되어 있는 경우
-굳이 위 경우들을 방지하고 싶다면 기준 원소를 잡을 때 맨 앞의 원소나 뒤의 원소를 잡지 말고 임의로 한 원소를 고르고 이에 맞추어 분할 알고리즘을 조금 바꿔주면 된다
-퀵 정렬이 성능이 좋지 않은 경우 세 번째는 동일한 원소가 많이 존재하는 경우이다
-입력의 모든 원소가 동일한 극단적인 경우라면 이미 정렬된 입력에서처럼 분할의 균형이 항상 최악이 된다.
-모든 원소가 동일하지 않더라도 중복이 무시하지 못 할 정도로 있으면 그에 비례하여 성능이 떨어진다.
-퀵 정렬을 진행하다보면 같은 원소들은 덩어리로 모이는데, 알고리즘은 이 사실을 알지 못 한 채 분할을 시도한다.
-이는 간단히 해결 가능, 분할 알고리즘에서 기준 원소와 동일한 원소를 만나면 양쪽에 골고루 나누어주도록 변경한다.
**자바로 퀵정렬 구현
public static void quickSort(int[] arr, int left, int right)
{
int i, j, pivot, tmp;
if (left < right) {
i = left;
j = right;
pivot = arr[left];
//분할 과정
while (i < j) {
while (arr[j] > pivot) j--;
while (i < j && arr[i] <= pivot) i++;
tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
arr[left] = arr[i];
arr[i] = pivot;
//정렬 과정
quickSort(arr, left, i - 1);
quickSort(arr, i + 1, right);
}
}'C \ C++ > 알고리즘 예습 스터디' 카테고리의 다른 글
| 11. 그리디 알고리즘 (2) (0) | 2024.02.04 |
|---|---|
| 11. 그리디 알고리즘 (1) (0) | 2024.02.01 |
| 9. 동적 프로그래밍 (0) | 2024.01.28 |
| 4. 정렬 (3) - 힙, 기수 정렬 (0) | 2024.01.28 |
| 4. 정렬 (1) - 선택, 버블, 삽입 정렬 (0) | 2024.01.19 |



