

archive
7. 오버피팅(Overfitting) & 언더피팅(Underfitting) 본문
1. 오버피팅
- 스키니진 회사를 착수하려고 하는데, 모든 스키니진을 슈퍼모델들의 몸 사이즈에 맞게 제작하여, 다양한 체형을 가진 소비자층의 타겟팅에 실패한 경우와 비슷한 머신러닝의 경우이다
-슈퍼모델들의 스키니진핏 데이터를 가지고 모델을 학습해 머신을 발표, 하지만 실제 세계의 테스트 데이터 (unseen data) 들은 학습데이터보다 훨씬 더 광범위한 경우
- 우리가 아직 모르는 데이터에 대해서 classifier가 제대로 작동을 못 할 경우 overfitting이라고 할 수 있는 것
-즉, 오버피팅이란, 현재 가지고 있는 데이터에서는 잘 작동을 하지만, 외부의 새로운 데이터에서는 작동을 잘 하지 않는 경우

- 머신러닝에서는 decision boundary 안에 있는 점들을 true로 설정, 밖을 false
- 따라서 위와 같은 그래프에 unseen data인 다양한 체형을 가진 데이터에 대해 classifier가 거짓이라고 판단할 수 있게 된다
- 결과적으로 decision boundary의 설정이 잘못되었음을 알게 되는 계기를 마련하게 되고, 이에 따라 decision boundary를 수정하게 된다

-따라서 다양한 사이즈를 고려한 decision boundary를 재설정하고, 오버피팅을 극복한 것을 볼 수 있음
-오버피팅을 극복할 수 있는 방법
-가장 먼저 해야할 일은 validation test set을 갖추는 것 -> 테스트 정확도가 트레인 데이터보다 낮게 되면 오버피팅된 모델임을 확인
(1) 교차 검증 (Cross Validation) : K-fold Cross validation
: 각각의 round마다 정확도를 측정하고, 그 정확도 값의 평균이 최종 정확도가 되는 방식
-최종 정확도가 train 정확도보다 낮게 되면, overfitting, 트레인 과정을 바꿔야 함 -> 정규화 과정을 거쳐야 함

(2-1) 정규화 (regularization)

- 조금 더 정교한 일반화가 필요하다는 필요에 의거하여 고안된 방안
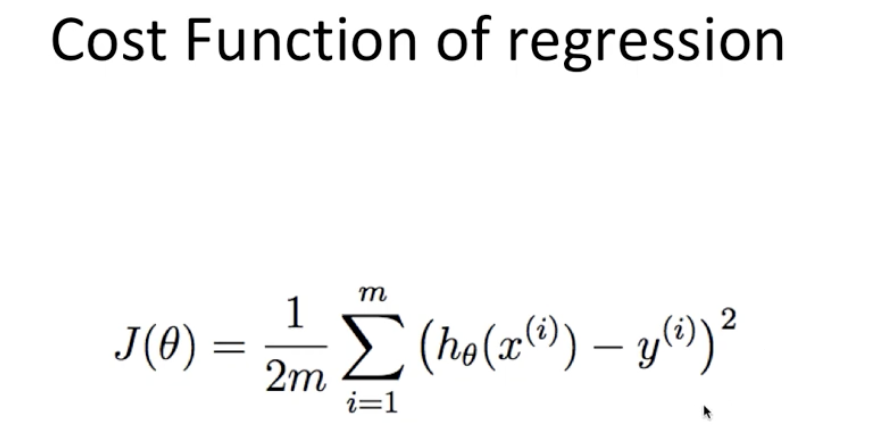
-비용함수에 대한 설명 : 예측값과 실제값의 차이를 평균낸 값 -> 이 값을 최소화할 경우 가장 이상적인 선형함수가 그려지게 된다
- variance를 낮추는 방법


- 세타 값을 절반으로 줄이게 되었을 때 가팔랐던 선이 조금 더 온화해짐, 미분값이 적어졌음 (gradient)
-즉, variance가 낮아지고, 선이 일반화되었다고 이야기할 수 있음
(2-2) Early Stopping 기법 (딥러닝)

-계속해서 학습을 시키게 된다면 (어느 지점을 넘어서는 순간부터는) 가지고 있는 데이터 셋에 대해서는 잘 맞추게 되지만 (Train accuracy 는 상승하겠지만), validation accuracy에 대해서는 하강하는 시점이 존재한다
- 그 직전인 포인트 (Early Stopping point)에서 학습을 멈추는 것
(2-3) Drop out (딥러닝)
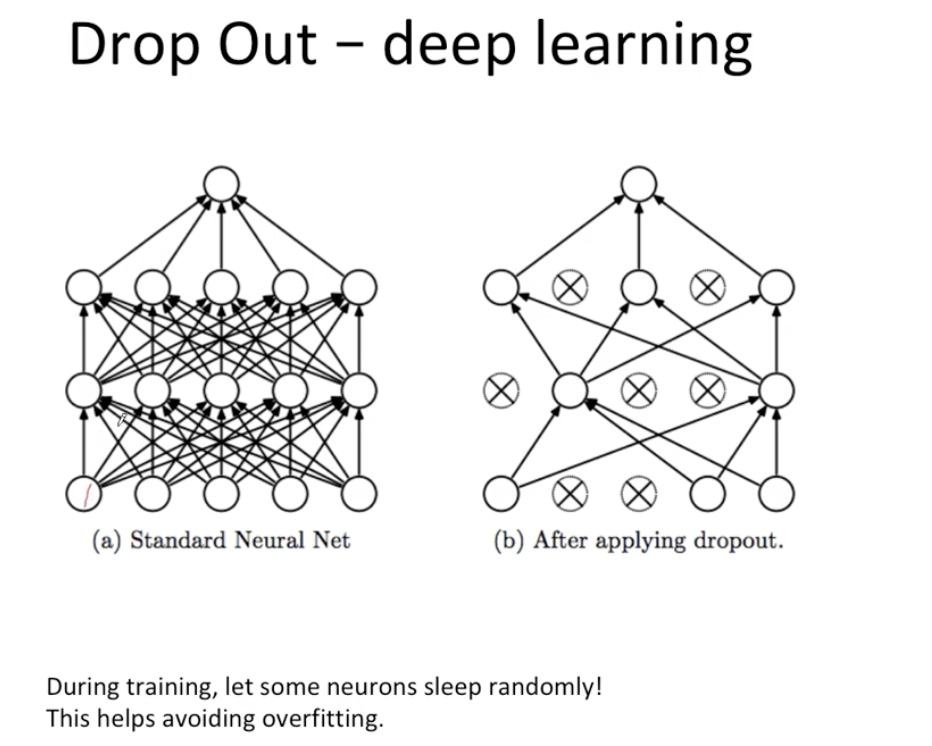
-트레이닝 과정에서 몇 개의 뉴런을 쉬게 만드는 방법론
(3) 데이터를 최대한 많이 추가 -> eg) 다양한 체형
**bias
: 머신러닝에서 학습 시 너무 데이터가 편향이 된 경우
: "공"이라는 개념을 학습해야하는데 분류 기준을 "둥글다" 밖에 주지 않은 경우 -> 사과도 양파도 모두 공이라고 분류
-bias가 높은 모델 -> underfitting 진단을 내릴 수 있음
-더 많은 variation과 적은 bias를 모델에게 노려야 함
ex) 머신이 있음, 집에 있는 축구, 야구, 농구 공을 가지고 "공"이라는 데이터를 학습시키려고 함
-> 둥굴어야하고, 먹을 수 없으며, 가지고 놀 수 있는 특성을 가진 "공"이라는 데이터
-> 둥글다 라는 특성만 주어진 경우 : Bias 가 높아 underfitting 진단
-> 둥글다, 못 먹는다, 가지고 놀 수 있다, 실밥이 있다, 지름이 70 이상이다, 가죽재질이다 라는 특성이 주어진 경우 : Overfitting

-Bias 의 의미 : 실제 값에서 얼마나 멀어져 있는가에 대한 척도
-Variance의 의미 : 예측된 값이 얼마나 서로 간에 많이 떨어져있는가
-underfitting 모델의 경우 high biased model -> 실제 값과 상당히 멀어져 정확도가 떨어짐
-overfitting 모델의 경우 high variance
-타겟 모델은 low bias & low variance -> 파란색 타겟 점들이 모두 붉은색 목표 지점 안에 들어와있는 것 -> 가장 이상적인 모델

- 가장 왼쪽 부분이 "둥근 것은 공이야" 라고만 가르친 경우, 즉 bias가 높은 상태, underfitting
- 가장 오른쪽 부분이 너무 많은 조건들을 가르친 경우, 즉 high variance, overfitting
-즉 fit 의 이상점을 발견하여 모델을 구축하는 것이 엔지니어들의 최종 목표하고 할 수 있다
-underfitting 극복할 수 있는 방법
(1) 더 많은 특징들을 찾아내어서 머신에게 학습
(2) 의사결정트리, k-nn, svm 과 같은 high variance 특징의 머신러닝 모델을 활용한다
'ML_AI > Inflearn 머신러닝 이론 및 파이썬 실습' 카테고리의 다른 글
| 8. Norm(L1, L2), PCA 차원 축소 (0) | 2024.02.18 |
|---|---|
| 5. 클러스터링 알고리즘 및 파이썬 실습 (0) | 2024.02.08 |
| 4. Linear regression, 선형 회귀 (0) | 2024.02.08 |
| 3. 나이브 베이즈(Naive Bayes) 분류 (0) | 2024.02.08 |
| 2. 의사결정트리, ID3 알고리즘 (0) | 2024.02.08 |



