

archive
[6주차 (2)] 뉴럴 네트워크 -MLP 본문
1. Neural Network
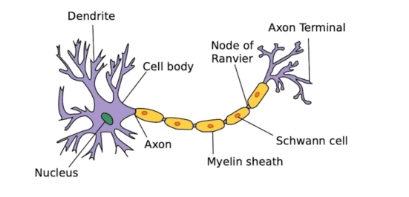
-인간의 신경망 구조에서 희미하게 영감을 받아 제작
-Neural Network는, 내가 정의한 함수로 투입값을 근사하는 수학적인 예측기이다. 행렬의 곱셈과 activation function(비선형 연산)이 반복적으로 일어남
- 어떤 변환을 위한 함수를 모방하는 function approximator
2. Linear Neural Networks

-선형회귀의 목적 : 입력이 1차원이고 출력이 1차원일 때, 2개의 값을 연결하는 가장 이상적인 값을 찾는 것
-파라미터는 가중치 w와 y 절편 b이다.
-우리의 목적은, N개의 데이터를 가장 잘 대변할 수 있는 하나의 선을 찾아내는 것
-그리고 Loss Function은 실제 데이터 값과 실선 사이의 차이 (LSM)을 줄이기 위해 정의하는 것, 즉 우리가 최소화시켜야 하는 대상
-즉, loss를 최소화하는 파라미터 w와 b를 줄여야함 ---> 데이터가 작을 때 등과 같은 많은 제약 조건이 따름

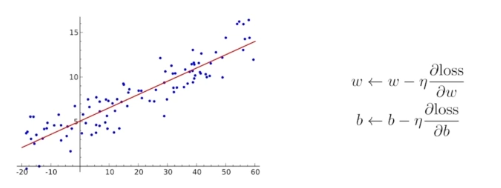
-Back Propagation (역전파) : 파라미터를 어떤 방향으로 움직였을 때 Loss function이 줄어드는지, 그리고 그 방향으로 바꾸는 것이 우리의 목표
-Loss Function을 파라미터로 각각 미분한 방향의 음수 방향으로 파라미터를 업데이트
-이와 같이 파라미터를 계속해서 업데이트해 나가는 방식을 Gradient Descent라고 명칭함
-적절한 step size을 설정하는 것이 좋음, optimize를 할 때 adaptive step size를 활용해 자동으로 최적화된 학습률을 설정할 수 있음

- 두 개의 벡터 스페이스 사이의 변환이라고 할 수 있음
-선형성을 가지는 변환이 있을 때 행렬로 표현하게 되는데, 이도 같음--> w와 b 행렬을 활용해서 x 의 데이터공간에 있는 데이터 점들을 y의 데이터 공간으로 보내어 변환시키겠다는 의미를 가짐
3. Deep Learning, Multi Layer Perceptron 다층신경망
-하나의 얇은 층이 아니라 여러 개의 deep한 층으로 쌓겠다는 의미
-사실 이는 행렬 두 개의 곱을 여러개 쌓는 것이기 때문에 한 단짜리 NN과 다를 것이 없어짐, 그래서 중간에 Non-linear transform function이 필요함
-매핑을 표현할 수 있는 표현력을 최대한 극대화하기 위해서는, 단순히 선형 결합을 여러 번 반복하는 것이 아니라, 선형 결합이 한 번씩 반복될 때마다 그 뒤에 activation fuction (signoid 등)을 곱해서 non linear transformation을 반복
--->이가 단순한 shallow learning과 다른 점이다
** Activation Function

- Loss Function : MSE를 줄이는 것이 1층 짜리를 줄이는 방법

- minimize 대상에 따라, 즉 Loss function을 무엇으로 설정하느냐에 따라 NN자체가 성질이 조금 달라지게 됨
-학습데이터의 에러 성질이 다르기 때문, 최적화된 함수가 존재함
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
'ML_AI > 네이버 부클 AI 엔지니어 기초 다지기 : AI Tech 준비과정' 카테고리의 다른 글
| [6주차 (4)] 최적화 - 2 (0) | 2024.06.02 |
|---|---|
| [6주차 (3)] 최적화 - 1 (0) | 2024.06.02 |
| [6주차 (1)] 딥러닝 기초 (0) | 2024.06.01 |
| [5주차 (1)] 확률론 (0) | 2024.05.25 |
| [4주차 (4)] 딥러닝 학습방법 이해하기 (0) | 2024.05.20 |



