

archive
[7주차 (2)] Sequential Model - Transformer - 1 본문
[7주차 (2)] Sequential Model - Transformer - 1
안정민 2024. 6. 7. 18:221. Transformer

-Sequential data를 다루는 모델
-왜 등장하게 되었나 ? ) 문장은 길이가 항상 가변적, 하나의 입력이 sequential하게 들어가게 되면, 중간에 데이터가 하나 빠지게 되거나 누락, permutated되는 경우에 다루기가 어려워짐

- 재귀적인 RNN과 달리 Transformer은 재귀적 구조가 없고, sequence를 다루는 모델이나 attention이라고 불리는 모델을 활용해서 대처
-

-어떤 문장이 주어지면 그걸 다른 언어 문장으로 바꾸는 것
-sequence를 인풋으로 사용하고 또 다른 sequence로 바꿔내는 것이 해당 모델의 목적

-입력은 세 단어로 구성된 불어 문장, 출력은 네 단어로 이루어진 영어 단어
- (1) 입력 시퀀스와 출력 시퀀스의 단어 수가 다를 수 있음
- (2) 입출력 도메인은 다르나 하나의 모델을 활용한다
-RNN의 경우 3개의 단어가 들어가면, 각각의 단어를 담당할 세 개의 모델을 요구하였음
-그러나 Transformer의 경우 몇 개의 입력이 들어오든 재귀적으로 돌지 않고 한 번의 self-attention으로 n개의 단어를 한 번에 처리할 수 있는 모델임
- 동일한 구조를 갖지만 네트워크 파라미터가 다르게 학습되는 두 개의 인코더와 디코더 활용
2. Encoder가 가변적인 N개의 단어를 한 번에 처리할까?

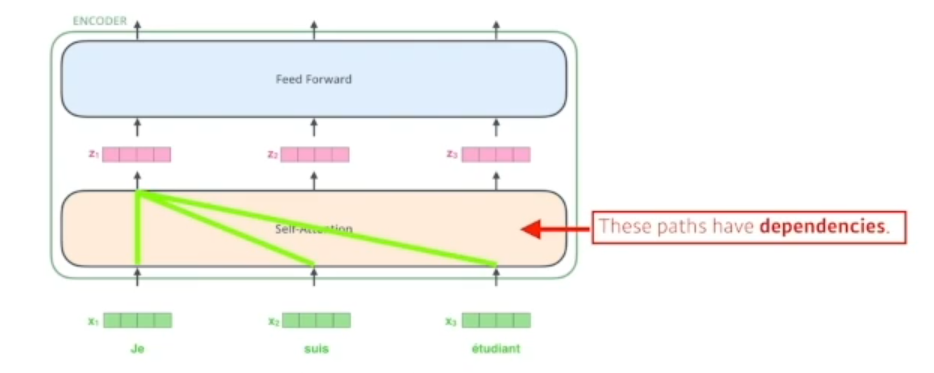
-N개의 단어 input, (self-attention이라는 단계와 Feed Forward Neural Network 단계) 두 단, 즉 한 단씩 거치는 것이 하나의 인코더, 즉 인코더가 쭉쭉 스택이 되게 된다
-self attention은 transformer의 성능을 보장하는 기술
STEP 1) 각각의 단어를 임베딩 벡터로 표현한다

STEP 2) 각 다른 도메인의, 벡터에서 벡터를 찾아서 매칭, 하나의 벡터에 상응하는 벡터를 찾아줄 때 해당 단어의 벡터값만을 활용하는 것이 아니라, 나머지 단어들의 벡터들도 고려하여 상응하는 벡터를 찾아서 매칭함
N개의 x 벡터가 주어지고 이에 상응하는 N개의 z 벡터를 찾는데, 각각의 i 번째 x 벡터에 상응하는 z 벡터를 찾을 때 i번째의 정보만 활용하는 것이 아닌 i 이전의 정보들 (past informations)도 활용하여 상응값을 찾아주는 것이 차별점
따라서 self attention은 dependancy가 존재한다, 나머지 벡터들을 활용하기 때문, Feed forward는 depandancy는 없고 한 번 통과해서 변환해주는 것에 불과하다.
-우리가 하나의 문장에 있는 단어를 설명할 때, 그 단어만을 고려하는 것이 아니라 그 단어가 문장 속에서 다른 단어들과 어떻게 상호작용을 하며 뜻을 만들어내는지가 중요한 것

-Transformer은 위의 단계에서 it이라는 단어와 다른 단어들 사이의 연관성에 초점을 맞추게 됨
-it이 animal과 높은 연관성을 가지게 된다고 학습하게 되는 원리이다.

-기본적으로 self attention모델은 단어가 주어졌을 때 3가지 벡터를 만들어내게 된다, 즉 3개의 Neural Network가 있다고 생각하면 된다.
- Query, Key, Value 벡터들은 주어진 하나의 단어에 대해 생성되게되며, 이 3개의 벡터들에 입각하여 새로운 도메인의 벡터로 변환하게 된다.

- 이와 같이 단어가 주어지면 query, Key, Value 벡터를 각각 만들어낸다
- 그러면 첫 번째로 해 주는 것은 score 벡터를 만들어낸다, 이 score 벡터의 경우 i 번째 단어에 대한 내가 인코딩을 하고자 하는 벡터의 (단어) 쿼리 벡터와, 나머지 모든 N개의 벡터들의 key 벡터를 구하여서 내적을 함
-얼마나 각 단어와 해당 단어들이 allign 되어있는지 확인하기 위한 단계
-i 번째 단어가 나머지 단어들과 얼마나 유사도가 있고 interaction이 있는지 확인, 그리고 이를 알아서 학습하게 함, 그리고 이것을 바로 attention이라고 부르는 것

-내적을 한 다음 score 벡터가 나오면, 이 벡터를 normalize하는 단계를 거친다.
-8로 나누는 이유, score 벡터가 특정한 수의 범위 안에 위치하도록 조정하기 위해서 나누는 과정임, 키 벡터에 dimension에 따라 나눠지는 수가 결정, 이 경우에는 64개의 key 벡터들을 생성해냈고, 이의 제곱근값인 8을 나누기 분모로 활용
-따라서 key벡터의 차원 혹은 query 벡터의 차원의 square root를 취한 값으로 나눠주게 된다
-그리고 softmax를 취하게 되면 interaction 값이 수로 도출되게 되고, 이를 attention rate라고 한다.

-스칼라로 표현된 attention rate
-최종적으로 직접 내가 사용할 값은 각각의 단어의 임베딩에서 나오는 value 벡터들의 weighted sum이 되는 것이다.
-이 최종 연산 값이 최종적으로 도출되는 i번째 단어에 해당하는 인코딩 벡터가 되는 것이다.
-따라서 이 과정을 통해 인코딩 벡터가 생성된다.
**Query 벡터와 Key 벡터는 항상 차원이 같아야 함 -> 둘이 내적을 해야 하기 때문이다
**하지만 Value 벡터는 차원이 달라도 됨, weighted sum만 계산하면 되니까
**최종적으로 나오는 인코딩 벡터의 차원은 value 벡터의 차원과 동일하다
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
'ML_AI > 네이버 부클 AI 엔지니어 기초 다지기 : AI Tech 준비과정' 카테고리의 다른 글
| [7주차 (4)] Generative Models - 1 (0) | 2024.06.09 |
|---|---|
| [7주차 (3)] Sequential Model - Transformer - 2 (0) | 2024.06.08 |
| [7주차 (1)] Sequential Model -RNN (0) | 2024.06.07 |
| [코드 리뷰 프로젝트] 2레이어 인공신경망 구현 백업 (0) | 2024.06.06 |
| [코드 리뷰 프로젝트] 경사하강법 구현 백업 (0) | 2024.06.06 |



