

archive
Lecture 1 - Basics 본문

1. Speech Recognition
음성 인식이란 사람이 말하는 음성 언어를 컴퓨터가 해석해 그 내용을 문자 데이터로 전환하는 처리
STT, 즉 Speech to Text라고도 함
2. Loss Function
손실함수란, 하나의 데이터 혹은 하나의 배치 사이즈의 데이터를 x라고 하고 그의 대한 ground-truth label을 t, 모델 아웃풋을 y라고 한다면 y와 t 사이의 거리를 측정하는 방법론
3. Entropy
엔트로피는 무작위 시행의 결과를 식별하여 전달되는 정보의 기대(즉, 평균) 양을 측정
변수의 잠재적 상태 또는 가능한 결과와 관련된 불확실성 또는 정보의 평균 수준을 정량화합니다. 이는 모든 잠재적 상태에 걸친 확률 분포를 고려하여 변수의 상태를 설명하는 데 필요한 예상 정보량을 측정
4. Backpropagation

Gradient update rule에 따라서 미분값에 learning rate을 곱한 값을 기존의 gradient에서 뺌 -> 이를 새로운 gradient로 채택
**gradient 계산 방법 : Chain rule 활용

5. Backpropagation Through Time (BPTT)
BPTT는 ★RNN에서 계산되는 역전파 방식★으로, sequential data의 특성으로 인해 발생하는 은닉상태를 따라 역행하면서 전파되는 gradient 계산 방법
RNN의 구조는 다음과 같음

input 이 x, state 가 c, hidden output이 h인 상황 (LSTM의 경우 h와 c는 모두 state라고 간주)
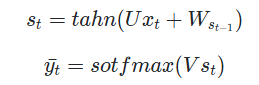
: input을 연결하는 가중치 행렬
: 현재 hidden state와 다음 hidden state를 연결하는 가중치 행렬
: output을 연결하는 가중치 행렬
이때 첫번째 셀의 loss값을 다음과 같이 정리할 수 있다.
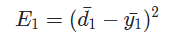
만약 Timestep = 3이라면 현재 model에서 update해야되는 weight matrix는 , , 3개가 존재합니다.
그렇다면 의 gradient를 구하기 위하여 에 대하여 로 편미분한 결과를 chain rule을 통해 구할 수 있다.
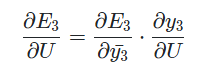
다음 의 gradient를 구하면 다음과 같다.
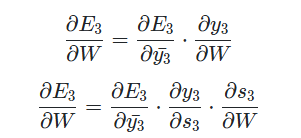
하지만 기존 backpropagation과는 다른 점이 각 timestep이 gradient에 영향을 주었기 때문에 를 상수 취급할 수 없다. 현재 timestep이 3인 출력 부분까지의 이전 timestep이 적용되기 때문에 t=2, t=1 까지 gradient를 전부 더해야한다. 그렇다면 다음과 같이 정리할 수 있다.
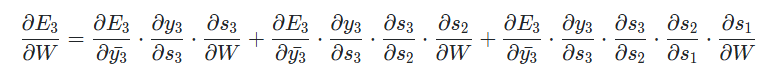
간단하게 정리하면 다음과 같은 식으로 정리할 수 있다.
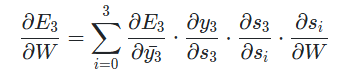
그리고 도 chain rule을 내포하고 있기 때문에 로 나타낼 수 있다. 위의 gradient를 다시 써보면 다음과 같이 나타낼 수 있다.
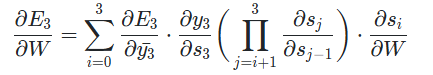
하지만 BPTT를 진행하다보면 처음부터 끝까지 모든 loss를 backpropagation해야하기 때문에 계샨량이 너무 많아지는데, 이것을 줄이고자 Truncated-Backpropagation Through Time(생략된-BPTT)를 많이 사용한다.
(+) RNN

"work" 가 동사로 매핑되는 것은 이전의 "I"가 pronoun이라는 것에 연관을 받은 판단임
즉, "I"의 hidden state 값이 그 다음으로 전달되어 "work"에 대한 데이터 매핑에 영향을 주었다는 것

여기서 xi는 input 데이터 값, hi는 은닉값, yi는 출력값을 의미
h1에서 나가는 지점에 주목 => output값 y1로 나가는 값과 state 값 h2로 나가는 값이 동일하다는 것을 알 수 있음
** 두 가지 weight이 존재, state 가중치(Whi)와 입력값가중치(Wxi)
각각 가중치를 곱한 다음 두 개의 값을 더하여 최종 output 값을 계산하도록 설계가 되어있음
추가적으로 bias 값이 더해짐
tanh 함수를 곱해주어서 전체적인 모델의 비선형성을 보장해 주게 된다.
yi로 나가는 값이나 그 다음 state 값으로 전달이 되는 값이나 둘 다 tanh가 씌워진 값이다
**모델의 가장 위에는 softmax 함수를 취해줌 -> 확률 값을 알 수 있음
이 모델은 supervied learning, 각 클래스에 대한 output 값의 확률을 계산하여 알 수 있고, 해당하는 값에 데이터를 매핑
(+) RNN 학습 과정

학습의 목표 = 정답 레이블과 모델 학습값 사이의 차이을 최소화하는 것
위의 그림에 나와있는 Wxh, Whh, b 는 여러번 등장하지만 하나의 시퀀스에 대해 동일한 값이 사용되는 단일 변수임
따라서 시퀀스에 따라 가중치가 달라지지 않음
Backprop이라고 하지 않고 각 time series마다 있는 동일한 변수를 바꾸는 것이기 때문에 Backpropagation Through Time (BPTT)라고 부르게 됨
(+) Sentiment Analysis 를 RNN으로 구현하는 방법

Sentiment Analysis 모델의 경우에는 마지막 state 값이 굉장히 중요함
따라서 결과값을 마지막 state 값으로 지정하고 이 값에 대해 softmax 함수를 취해주어 prediction을 구하게 된다
이 또한 동일한 단일 변수들을 사용하기 때문에 BPTT를 활용하여 이상적인 가중치값을 찾아나가야 함
이러한 모델을 단순화하여 다이어그램을 그려본다면 다음과 같아진다
