

archive
9. Transformers 본문
https://web.stanford.edu/~jurafsky/slp3/9.pdf

9.1 Attention
word2vec 과 같은 static 임베딩 => 단어에 대한 표현이 문맥 context와 아무 관련 없이 항상 동일한 고정된 벡터값을 가진다는 사실을 알고 있음
따라서 it, her 등과 같은 pronoun의 경우에는 문장 속에서 문맥이 굉장히 의미를 많이 좌우함 -> 문맥적인 요소가 담겨있지 않은 static embedding을 활용하게 되면 모델의 성능이 떨어지게 됨

위의 예시에서 9.1의 "it" 은 "chicken"을, 9.2 에서의 "it"은 "road"를 지칭한다.
만약 우리가 이 문장들의 의미계산을 한다고 했을 때, 문맥에 예민하게 해석을 할 수밖에 없는 상태
이외에도 많은 경우에 단어들은 문장 속에서 다른 단어들과 rich linguistic relationships을 가지고 있음
따라서 Transformer은 "contextual embedding"을 실시
=> 유용한 컨텍스트 단어의 의미를 통합하여 단어 의미의 컨텍스트 표현인 컨텍스트 임베딩을 구축
레이어를 거듭할 수록 더 풍부한 문맥적인 표현을 단어의 임베딩 속 구축할 수 있게 됨
각각의 레이어에서는 이전까지에 대한 hidden state에서 현재의 input 만들어 냄 -> 각 위치에서 각 단어에 대한 컨텍스트 표현을 생성

Attention Layer는 k-1까지의 layer에서의 문맥을 적절한 가중치를 부여해 결합한 값을 k 현재 토큰에 대한 표현을 구축하는데 이용
layer k에서 모든 이전 토큰의 표현을 활용하며, self-attention 분포를 사용하여 "it"과 관련된 중요한 단어에 더 높은 가중치를 부여
그림에서 어텐션 분포는 색상의 진하기로 나타내며, 더 진한 색상은 더 높은 어텐션 가중치를 의미
Transformer는 특히 "chicken"과 "road"라는 토큰에 높은 어텐션을 부여 -> "it"이 문맥상 이 두 단어와 coreference(공지시 관계)를 형성할 가능성이 있기 때문
(1) Attention more formally
즉, Attention 계산은 특정 Transformer 계층에서 토큰의 벡터 표현을 계산하는 방법으로, 이전 계층의 토큰들로부터 정보를 선택적으로 주목하고 통합
어텐션은 입력 표현 xi (위치 의 입력 토큰에 해당)와 이전 입력 x1부터 xi−1까지의 컨텍스트 창을 받아들이며, 출력 ai를 생성
일반적으로 좌->우 언어모델에서 context란 모든 이전 단어에 대한 정보를 의미함
xi 입력을 프로세싱할 때, output을 만들어내기 위해서는 input xi 와 xi-1까지의 모든 토큰의 표현을 사용할 수 있음
그러나 i 이후의 토큰들은 접근이 불가능
즉, 이전까지의 문맥만 현재 단어 토큰 입력에 관여 가능함
본질적으로, 어텐션(attention)은 컨텍스트 벡터의 가중 합(weighted sum)에 불과
어떤 위치 i에서의 어텐션 출력 a는, 단순히 이전 입력 표현 xj의 가중 합으로 계산
여기서 가중치 αij 는 xj가 ai에 얼마나 기여해야 하는지를 나타냅니다.

각 αij는 ai를 계산하기 위해 xj값을 가중합에 추가할 때 사용되는 스칼라 값 즉 weight 값임
어텐션에서는 현재 토큰 (timestep = i)와 이전 토큰 (timestep <=j) 간의 유사성(similarity)에 비례해 각 이전 임베딩의 가중치를 설정
즉, 어텐션의 출력은 이전 토큰들의 임베딩 값에 대해, 현재 토큰 임베딩과의 유사성에 의해 가중치를 부여한 합
우리는 유사성을 내적(dot product)으로 계산 -> 이는 두 벡터를 스칼라 값으로 변환하며, 값의 범위는 −∞에서 .
이 점수는 소프트맥스(softmax)로 정규화되어 αij의 벡터를 생성


예를 들어, 위의 에서 우리는 a3를 계산할 때 세 가지 점수를 계산:
- x3⋅x1, x3⋅x2, x3⋅x3
그 후, 이 점수들을 소프트맥스 함수로 정규화하여, 각각의 가중치가 현재 위치 에 대해 비례적으로 중요도를 나타냄
그 결과 값(확률)을 사용하여 a3를 계산
소프트맥스 가중치는 현재 입력 xi에서 가장 높아짐 -> 가 스스로와 매우 유사하기 때문에 높은 내적 값을 갖기 때문
하지만, 다른 컨텍스트 단어들도 xi와 유사할 수 있으며, 소프트맥스는 그 단어들에게도 가중치를 할당합니다.
우리는 이 가중치 값을 α로 사용하여 가중 합을 계산하고 최종적으로 ai를 얻습니다.
(2) Query, Key, Value 행렬을 활용한 Single Attention Head
Head 라는 단어는 특정한 구조화 된 계층을 의미하는 데에 사용되는 단어
Attention head는 각 입력 임베딩이 어텐션 과정에서 담당하는 세 가지 다른 역할을 구별하여 나타낼 수 있음
| Query | 현재 입력이 이전 입력과 비교 어떤 관련성이 있는 지에 대한 질문을 물어보는 주제 ex) "it" |
| Key | 현재 입력과 비교되는 이전 입력이 유사성을 결정하기 위해 가지는 역할 attention을 수행할 대상, 즉 이전까지 입력된 벡터 ex) "The", "chicken", "didn't", "cross", "the", "road", "because", "it" |
| Value | 현재 입력의 출력을 계산하기 위해 가중합되는 이전 입력의 값 |
이 세가지 역할을 수행하기 위해 transformer 구조는 가중치 행렬 WQ, WK, WV를 도입 -> 이 가중치 행렬은 입력 벡터 xi를 query, key, value 로의 representation으로 투영하는 역할을 수행한다

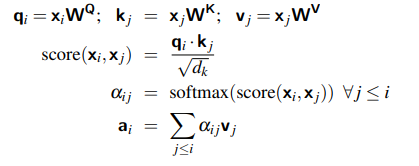
이러한 사영 작업 후 현재 입력과 이전 입력 간의 유사성 계산
=> ( 현재 입력의 query 벡터 qi ) * (이전 입력의 key 벡터 kj )
=> 즉 두 값의 내적 값을 유사도로 활용
그러나 이 내적의 값은 양의 방향이든 음의 방향이든 너무 큰 값이 나올 수 있음, 이러한 값은 계산 상의 문제를 발생시킴 (Gradient Descent 시 기울기 발산, 수치적 불안정성 문제)
따라서 이러한 계산 상의 불이익을 피하기 위해 내적의 결과를 query와 key 벡터 차원의 제곱근으로 나누어 스케일링을 진행
이를 통해 안정적인 소프트 맥스 계산을 보장한다.
즉 위의 식을 정리하면 다음과 같다
| 유사성 점수 |  |
| 가중치 계산 |  |
| 최종 어텐션 출력 |  |

입력벡터 xi와 어텐션 출력 ai는 모두 동일한 차원 1*d를 가짐 => 해당 차원을 모델 차원 (model dimentionality)라고 함
key와 query 벡터의 차원은 1*dk 이고, value 벡터의 차원은 1*dv
따라서 변환 행렬의 차원은 다음과 같다

해당 행렬을 곱해줌으로써 key와 query 벡터의 차원을 모델 차원으로 사영시킴
요약하면 다음과 같다 :
- 어텐션 헤드는 입력 벡터 xix_i를 query, key, value로 변환하여 프로세스를 수행
- 내적을 통해 유사성을 계산하고, 소프트맥스를 사용해 가중치를 정규화
- 각 입력의 출력 a는 가중치에 따라 value 벡터들의 합으로 계산
(3) Multi-head Attention
사실 transformer 는 multi-head Attention 구조를 활용
직관적으로, 각 헤드는 다른 역할을 수행하기 위해 컨텍스트에 주목 -> 예를 들어, 어떤 헤드는 특정 관계를 캡처하고, 다른 헤드는 컨텍스트 내 특정 패턴을 감지
따라서 Multi-head Attention은 하나의 모델에서 병렬로 독립적인 어텐션 헤드를 사용
즉, h개의 분리된 독립된 어텐션 헤드가 존재
=> 나동빈에서 h개의 서로 다른 attention 컨셉을 학습하도록 유도하는 과정, 더욱더 구분된, 다양한 특징을 학습하도록 하는 것이라고 설명했던 부분
각 헤드는 자체적인 key, query, value 가중치 행렬 (WQ,WK,WV)을 가지게되는데, 이를 통해 입력을 별도의 key, query, value 임베딩으로 투영해서 구분된 독립 값을 각각 학습하는 원리임
Multi-head Attention에서도 입력과 출력의 모델차원은 d 로 동일하게 유지된다
Key와 Query의 임베딩 타원은 dk, 임베딩 차원은 dv 로 설정되며,각 헤드에 대해

위 연산을 수행해서 차원을 맞춰주는 과정을 거치게 됨
최종적인 계산 식은 다음과 같음

| 1. 각 헤드에 대해 Query, Key, Value 계산 |  |
| 2. 유사성 점수 계산 및 스케일링 |  |
| 3. Softmax 정규화 (가중치 계산) |  |
| 4. Weighted Value 계산 (각 헤드의 출력) |  |
| 5. 모든 헤드의 병렬 연결 |  |
각 헤드의 출력은 1*dv 차원의 형태를 가지게 됨
따라서 h개의 헤드의 출력은 1*h*dv 벡터로 병렬 연력되게 된다
이후 또 다른 선형 변환 (output 계산을 위한 가중치) Wo를 통해 최종 어텐션 벡터 ai로 투영된다.
9.2 Transformer Blocks
self-attention 계산은 transformer block 이라는 부분에 의존하는데, 이는 곧 self-attention layer라고 불린다
self-attention layer는 3가지 서로 다른 layer로 구성
(1) Feedforward Layer 피드포워드 레이어
(2) Residual Connection 잔차 연결
(3) Normalizing Layer 정규화 레이어

residual stream 의 관점에서 특정 입력 토큰 xi의 처리는 transformer 블록 내부를 통과하면서 d-차원의 표현 스트림으로 이어지게 된다
Residual Stream은 입력 벡터에서 시작하며, 각 구성 요소가 입력을 처리하고 결과를 Residual Stream에 다시 추가
#Residual Stream
Residual Stream의 최하단 입력은 토큰에 대한 임베딩 벡터로, 차원 d를 가짐
이 초기 임베딩은 Residual Connections 잔차 연결을 통해 위로 전달되며 , Transformer의 다른 구성 요소에 점진적으로 추가 -> Attention layer와 feedforward layer
#Layer Norm
Attention Layer와 Feedforward Layer 이전에 수행되는 연산
- 초기 벡터 처리:
- 초기 벡터는 Layer Norm과 Attention Layer를 통과합니다.
- 결과는 다시 스트림에 추가되며, 이 경우 원래 입력 벡터 xix_i에 추가됩니다.
- 합산된 벡터 처리:
- 합산된 벡터는 다시 Layer Norm과 Feedforward Layer를 통과합니다.
- 그 출력은 Residual Stream에 다시 추가됩니다.
- 최종 출력:
- 이렇게 반복적으로 처리된 결과를 hih_i로 표현하며, 이는 토큰 ii에 대한 Transformer 블록의 최종 출력을 나타냅니다.
Residual Stream에 대한 추가 설명
- 초기 설명에서 Residual Stream은 종종 **잔차 연결(residual connections)**이라는 다른 메타포로 묘사되었습니다.
- 잔차 연결은 컴포넌트의 입력을 출력에 추가하는 방식으로 작동합니다.
- 하지만 Residual Stream은 Transformer의 구조를 더 명확하게 시각화하는 방법으로 간주됩니다.
'ML_AI > 24_여름방학 인공지능 스터디' 카테고리의 다른 글
| 7. Neural Networks (0) | 2024.11.16 |
|---|---|
| [논문 리뷰] Attention Is All You Need (0) | 2024.09.22 |
| [논문 리뷰] Deep Residual Learning for Image Recognition (0) | 2024.08.07 |
| [교재] 9. 텍스트를 위한 인공 신경망 (0) | 2024.07.23 |
| [교재] 5. 트리 알고리즘 (2) (0) | 2024.07.10 |



