

archive
AI based detection of early cognitive impairment using language, speech, and demographic features 본문
AI based detection of early cognitive impairment using language, speech, and demographic features
안정민 2025. 1. 24. 14:01Dementia detection 프로젝트 세미나 발표 자료 백업

1. A New ML Approach
(1) ConceptNet 의 적용
LLM은 큰 규모의 데이터셋을 바탕으로 구축되는 모델임
대규모 데이터세트에 대한 의존도를 줄이기 위한 방법 -> 입력 데이터의 표현을 풍부하게 함
따라서 이 논문에서는 ConceptNet이라는 개념을 통해서 입력 데이터를 임베딩
ConceptNet
Sources of knowledge Previous versions of ConceptNet were a home-grown crowd-sourced project, where we ran a Web site (Open Mind Common Sense) collecting facts from people who came to the site. The Web of Data is much bigger than that now. Our data comes f
conceptnet.io
ConceptNet은 지식 그래프로, 자연어 단어 및 구를 연결하여 임베딩
즉 세상에 존재하는 일반적인 상식과 개념 간의 관계를 구조화하여 표현한 데이터베이스
노드는 단어 혹은 구문으로 이루어진 개념을 나타내고, 엣지는 이러한 개념 간의 관게를 나타냄
엣지로 나타내어지는 관계는 의미론적 관계 (semantic relationship)으로 정의 -> IsA, PartOf, UsedFor, Synonym, Antonym
이를 기반으로 단어 간의 관계를 벡터 공간에 매핑하여 단어 임베딩을 생성하는 데에 활용
Word2Vec, GloVe 와 같은 전통적인 임베딩 모델은 대량의 코퍼스를 통해 단어 간의 통계적인 관계를 학습,
ConceptNet 기반 임베딩은 단어 간의 상식적이고 명시적인 관계를 반영
나아가 단순히 문맥적 관계를 넘어서 IsA, PartOf, Synonym 등의 명시적인 "관계"를 포함하기 때문에, 임베딩 벡터가 더 구체적이고 직관적인 의미를 가지게 된다
따라서 이를 통해 생성된 풍부한 임베딩은 feature engineering에 활용
아래는 ConceptNet을 통해 생성된 결과물임

이와같이 엔티티들을 정규화시키고, 정해진 포맷으로 그들의 상호작용 관계를 정의를 가능하게 한다
(2) Cognitive Cross Domain Attention (CCDA) 의 적용
이 논문에서는 Cognitive Cross Domain Attention (CCDA)를 GPT3.5 모델에 적용함
CCDA는 서로 다른 영역에 attention을 적용하는 매커니즘
이 매커니즘은 모델이 한 영역의 정보를 다른 영역으로 전이하여 이해와 성능을 향상하도록
2. Used Data - Aging Brain Cohor Corpus
피실험자들은 동일한 태스크를 수행하도록 한 상태에서 인지 능력을 측정한 데이터베이스
attention, 프로세스 속도, 기억력, 실행 능력 등의 정보를 포함하는 데이터베이스


해당 데이터베이스는 연구자들로 하여금 건강한 노화와 뇌, 유전학, 행동적 특성 간의 관계성을 찾는 것을 가능하게 한다
3. Data Pre-processing
실험에 해당 데이터를 사용하기 전 238 개의 raw 음성 데이터를 텍스트 데이터로 변환

음성 데이터로부터 Table 4에 나타난 특징들을 추출해냄, 그리고 해당 특징들을 통해 MoCA 점수 추출, 피실험자를 3가지로 나누었음 (중증치매, 경증치매, 일반인)
4. Correcting for Class Imbalance
클래스 간 데이터 갯수의 불균형이 존재 -> SMOTE를 통해 데이터 불균형 조정
불균형 조정 후 각각의 클래스 별 180개의 데이터가 존재하는 균형이 맞추어진 데이터셋으로 변화함
10fold cross validation 진행, 모델 학습에 있어서 어떠한 데이터 손실도 없게 만들기 위해 적용
훈련 데이터에 대해 information gain 및 correlation coefficient를 사용하여 각 교차검증 단계마다 feature selection을 수행
두 요소를 통해 각 특징의 중요도를 평가, 최상위 30%의 중요한 특징만 선택하여 모델 훈련에 활용
과적합 방지를 위해 정보성이 높은 비중복 특징만 활용한다.
선택된 주요 특징들 : 어휘 다양성, 음향적 요소, 발화속도 등
5. Model Development and Validation
데이터셋은 9:1의 비율로 train:test 분할
평가에 활용된 모델은 다음과 같음
| 구분 | 모델 |
| ML model | BOW (Bag Of Words) + LR (Logistic Regression) |
| SVM (Support Vector Machine) | |
| Deep Learning Model | CNN |
| BiLSTM (Bidirectional Long Short Term Memory) | |
| BiLSTM-att (with attention) | |
| Context Embedding Model | BERT |
| BioBERT | |
| RoBERTa |
모델 학습 하이퍼 파라미터 요약
| 학습 에폭 | 학습률 | 배치크기 | 손실함수 | 옵티마이저 | dropout | 평가지표 |
| 10 | 1e-5 | 64 | cross entropy | ADAM | 0.2 | Recall, Precision, F1, AUC |
6. Knowledge Augmented LLM
ConceptNet을 활용하여 입력 텍스트의 개념 표현을 풍부하게 하였음
나아가 CCDA 라는 새로운 매커니즘을 채택하여 GPT-3.5 모델을 개선하였음
GPT 모델 -> 인코더에서 attention 매커니즘을 활용한 transformer 채택, 따라서 input 데이터를 인코딩할 때
ConceptNet을 사용하여 표현을 풍부하게 만들고, 지식그래프에서 관련 개념과의 관계를 검색함
이러한 풍부해진 임베딩은 우리의 모델에서 feature로 사용되어 그림 묘사 작업에 특화된 주요 개념을 활용하여 ConceptNet에 내재된 상식 지식을 사용할 수 있도록 하였다

이러한 추가적인 문맥적 정보는 모델이 개념 간의 의미와 관계를 더 잘 이해하게 도와주었으며, 이를 통해 성능 개선
이러한 외부 지식 소스를 활용하여 attention 메커니즘을 조정하고
특정 개념과 관련된 토큰에 더 높은 가중치를 할당하도록 모델을 미세조정
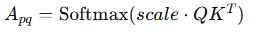

즉 attention 가중치 계산 공식이 제공되며, 이는 주어진 토큰 간의 관게를 정량화하여 모델에 적용
이를 통해 모델이 더 입력된 텍스트와 개념간의 관계를 더 깊이 이해하고, 그림 묘사 작업에서 더 높은 성능을 달성 가능
7. Result and Conclusion

인지 저하의 초기 징후를 발견하는 것은 의료 전문가들이 적절한 치료를 추천하고 생활 방식 및 식단 조정을 통해 인지 저하를 효과적으로 예방할 수 있도록 돕는 데 필수적입니다. 이 논문에서는 CCDA를 제안합니다. CCDA는 도메인 특정 지식 그래프(KG)로 강화된 새로운 크로스-어텐션 인지 도메인 모델로, 인지 장애 범위 내의 MoCA 점수를 감지하는 분류를 제공합니다.
이 모델은 예측 능력에 기여하는 단어나 구를 언어적 표현에서 식별하도록 설계되었습니다. 표 6의 결과는 크로스-어텐션 헤드에서 지식-강화 학습이 모델 성능을 최첨단 수준으로 끌어올리는 데 기여했음을 보여줍니다.
연구 결과에 따르면 CCDA는 인지 저하의 초기 징후 및 노인들의 언어 표현에서 다양한 수준의 인지 저하를 구별할 수 있음을 입증했습니다. 우리는 반복적인 언어, 혼란, 논리적 사고의 어려움, 일반적인 사물 이름을 기억하는 데의 어려움 등과 같은 언어 관련 증상들을 포함해 이 연구를 확장하려고 합니다.
이 접근법은 경제적으로 발전이 덜 된 지역에서 특히 유용할 수 있으며, 비용 효율적이고 비침습적인 해결책에 대한 높은 수요를 충족시킬 수 있습니다. 이 연구에 사용된 데이터는 실 참여자와의 직접적인 교류를 통해 수집되었습니다. 이 연구는 참여자들의 언어적 표현에서 발견되는 언어 패턴 분석에 중점을 둡니다.
'ML_AI > 논문 리뷰' 카테고리의 다른 글
| [2월 NLP 기초 논문 스터디] LoRA (PEFT) (0) | 2025.03.02 |
|---|---|
| [2월 NLP 기초 논문 스터디] BERT (Pretraining) (0) | 2025.03.02 |
| [2월 NLP 기초 논문 스터디] Dependency Parsing (0) | 2025.02.09 |
| [2월 NLP 기초 논문 스터디] GLoVe (0) | 2025.02.09 |
| [2월 NLP 기초 논문 스터디] Word2Vec (0) | 2025.02.09 |
