

archive
언론사 별 크롤링 소스코드 및 엑셀 정리 - 중앙일보 본문
원래 모든 소스코드마다 excluded 단어 배열 넣었었는데 객체지향 활용해서 excluded 파일 하나 만들고 그거 import 해서 사용한 거가 진짜 번거로움 줄인 거의 신의 한수였다고 생각
[중앙일보]
#제외단어 excluded 파일
excluded_words = [
# 기사관련 단어
"중앙일보", "이미지좋아요슬퍼요", "이미지화나요공유", "이미지공유기사추천", "이미지기사추천공유하기닫기copyright", "이미지", "추천", "공유", "기사", "기자", "공유", "뷰",
"콘텐츠", "연재", "이슈","일보",
# 의미없는 단어
"것", "등", "이", "수", "그", "김", "우리", "위", "위해", "때문", "또", "백", "의", "때", "경우", "및", "대해", "개", "구독", "날",
"이번", "지난해", "명", "내년", "관련", "지금", "연관", "대한", "전", "더", "이후", "올해","정도",
"현재", "데", "주", "하단", "심", "중", "도", "지난", "새", "로", "씨", "차", "달", "내", "노", "말", "속", "고", "를", "점", "며",
"일","통해","곳","뒤","건","게","안","모두","지난달","정","오후","오전","당시","당국","최근","가장","선","이상","상황","감소","대비","기준",
"약","이상","번","가장","세","해당", "은","제","최고","관계자","저","보고","보도","중앙","박","왜","지사","위원","두","층","라며","앞","당",
"듯","앞","여","두","물","후","띠","나","처음","거",
#논의필요
"확","진자"
]모든 언론사에도 적용이 되는 기준인데, 크게 의미 부여의 주체가 명확하지 않은 부사, 대명사, 그리고 언론사 관련 단어와 검색어는 모두 excluded 배열에 포함시켰다
[중앙일보 코로나 재난지원금 1차 지급 후 2달 기사 크롤링]
# 중앙일보 코로나 후
import excluded as ex
import requests
from bs4 import BeautifulSoup
from collections import Counter
import re
import numpy as np
import matplotlib.pyplot as plt
from konlpy.tag import Okt
plt.rc("font", family="Malgun Gothic")
html_urls = []
#한 번에 검색 결과 5000개까지만 표시, 전체 기사 7300개라서 구간을 나누어 배열에 추가
base_url = "https://www.joongang.co.kr/search/news?keyword=코로나&startDate=2020-05-01&endDate=2020-05-31&sfield=all&page={}"
for page in range(1,168):
url = base_url.format(page)
html_urls.append(url)
base_url = "https://www.joongang.co.kr/search/news?keyword=코로나&startDate=2020-06-01&endDate=2020-06-30&sfield=all&page={}"
for page in range(1,144):
url = base_url.format(page)
html_urls.append(url)
# 기사 미리보기 페이지에서 추출한 기사 목록 저장을 위한 빈 배열
urls = []
for url in html_urls:
response = requests.get(url)
# HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# URL 추출
cards = soup.select(
'div#wrapper>main#container>section.contents>div.row>section.chain_wrap.col_lg9>ul.story_list>li.card>div.card_body>h2.headline>a')
for card in cards:
article_url = card['href']
urls.append(article_url)
#####################
# 전체 단어 빈도를 저장할 Counter 객체
total_word_counts = Counter()
okt = Okt()
for url in urls:
response = requests.get(url)
# HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 기사 본문 선택
article_body_elements = soup.select(
'div#wrapper>main#container>section.contents>article.article>div#article_body.article_body.fs3>p')
for article_body_element in article_body_elements:
# 특수 문자 제거 및 소문자 변환
article_body = re.sub(r"[^\w\s]", "", str(article_body_element)).lower()
# 명사 추출
nouns = okt.nouns(article_body)
ex.excluded_words.extend(["코로나","코로나바이러스"])
# 단어 빈도 분석
word_counts = Counter(word for word in nouns if word not in ex.excluded_words)
# 단어 빈도를 전체 빈도에 누적
total_word_counts += word_counts
# 가장 많이 등장한 단어 50개 추출
top_words = total_word_counts.most_common(50)
# 시각화를 위한 데이터 준비
labels, counts = zip(*top_words)
x = np.arange(len(labels))
# 막대 그래프 그리기
plt.bar(x, counts, align="center")
plt.xticks(x, labels)
plt.xlabel("단어")
plt.ylabel("빈도수")
plt.title("중앙일보 코로나19 관련 기사 단어 빈도수 분석")
plt.show()
# 결과 출력
print("중앙일보 코로나19 관련 재난지원금 지급 후 기사 중 가장 많이 등장한 단어 50개:")
for word, count in top_words:
print(f"{word}: {count}")
# 사용자 입력 대기
input("Press Enter to exit...")[중앙일보 2008년 금융위기 발생 후 2달 기사 크롤링]
# 중앙일보 금융위기 후
import excluded as ex
import requests
from bs4 import BeautifulSoup
from collections import Counter
import re
import numpy as np
import matplotlib.pyplot as plt
from konlpy.tag import Okt
plt.rc("font", family="Malgun Gothic")
html_urls = []
base_url = "https://www.joongang.co.kr/search/news?keyword=금융위기&startDate=2008-09-14&endDate=2008-11-14&sfield=all&page={}"
html_urls = []
for page in range(1, 54):
url = base_url.format(page)
html_urls.append(url)
# 기사 미리보기 페이지에서 추출한 기사 목록 저장을 위한 빈 배열
urls = []
for url in html_urls:
response = requests.get(url)
# HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# URL 추출
cards = soup.select(
'div#wrapper>main#container>section.contents>div.row>section.chain_wrap.col_lg9>ul.story_list>li.card>div.card_body>h2.headline>a')
for card in cards:
article_url = card['href']
urls.append(article_url)
#####################
# 전체 단어 빈도를 저장할 Counter 객체
total_word_counts = Counter()
okt = Okt()
for url in urls:
response = requests.get(url)
# HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 기사 본문 선택
article_body_element = soup.select(
'div#wrapper>main#container>section.contents>article.article>div#article_body.article_body.fs3>p')
if article_body_element:
# 특수 문자 제거 및 소문자 변환
article_body = re.sub(r"[^\w\s]", "", str(article_body_element)).lower()
# 명사 추출
nouns = okt.nouns(article_body)
ex.excluded_words.extend(["금융", "금융위기"])
# 단어 빈도 분석
word_counts = Counter(word for word in nouns if word not in ex.excluded_words)
# 단어 빈도를 전체 빈도에 누적
total_word_counts += word_counts
# 가장 많이 등장한 단어 50개 추출
top_words = total_word_counts.most_common(50)
# 시각화를 위한 데이터 준비
labels, counts = zip(*top_words)
x = np.arange(len(labels))
# 막대 그래프 그리기
plt.bar(x, counts, align="center")
plt.xticks(x, labels)
plt.xlabel("단어")
plt.ylabel("빈도수")
plt.title("중앙일보 금융위기 관련 기사 단어 빈도수 분석")
plt.show()
# 결과 출력
print("중앙일보 금융위기 관련 기사 중 가장 많이 등장한 단어 50개:")
for word, count in top_words:
print(f"{word}: {count}")
# 사용자 입력 대기
input("Press Enter to exit...")[중앙일보 금융위기 1달 전 정치 부문 기사 크롤링]
# 중앙일보 금융위기 전 정치
import excluded as ex
import requests
from bs4 import BeautifulSoup
from collections import Counter
import re
import numpy as np
import matplotlib.pyplot as plt
from konlpy.tag import Okt
plt.rc("font", family="Malgun Gothic")
base_url = "https://www.joongang.co.kr/politics/general?startDate=2008-08-14&endDate=2008-09-13&page={}" #객관적인 자료 확보를 위해 아무 검색 키워드 없이 정치 면 크롤링 (정치일반)
html_urls = []
for page in range(1,8):
url = base_url.format(page)
html_urls.append(url)
# 기사 미리보기 페이지에서 추출한 기사 목록 저장을 위한 빈 배열
urls = []
for url in html_urls:
response = requests.get(url)
# HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# URL 추출
cards = soup.select(
'div#wrapper>main#container>section.contents>div.row>section.chain_wrap.col_lg9>ul.story_list>li.card>div.card_body>h2.headline>a')
for card in cards:
article_url = card['href']
urls.append(article_url)
#####################
# 전체 단어 빈도를 저장할 Counter 객체
total_word_counts = Counter()
okt = Okt()
for url in urls:
response = requests.get(url)
# HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 기사 본문 선택
article_body_element = soup.select(
'div#wrapper>main#container>section.contents>article.article>div#article_body.article_body.fs3>p')
if article_body_element:
# 특수 문자 제거 및 소문자 변환
article_body = re.sub(r"[^\w\s]", "", str(article_body_element)).lower()
# 명사 추출
nouns = okt.nouns(article_body)
ex.excluded_words.extend(["금융위기"])
# 단어 빈도 분석
word_counts = Counter(word for word in nouns if word not in ex.excluded_words)
# 단어 빈도를 전체 빈도에 누적
total_word_counts += word_counts
# 가장 많이 등장한 단어 50개 추출
top_words = total_word_counts.most_common(50)
# 시각화를 위한 데이터 준비
labels, counts = zip(*top_words)
x = np.arange(len(labels))
# 막대 그래프 그리기
plt.bar(x, counts, align="center")
plt.xticks(x, labels)
plt.xlabel("단어")
plt.ylabel("빈도수")
plt.title("중앙일보 금융위기 <1달 전 - 정치> 관련 기사 단어 빈도수 분석")
plt.show()
# 결과 출력
print("중앙일보 금융위기 <1달 전 - 정치> 관련 기사 중 가장 많이 등장한 단어 50개:")
for word, count in top_words:
print(f"{word}: {count}")
# 사용자 입력 대기
input("Press Enter to exit...")[중앙일보 코로나 1차 재난지원금 1달 전 정치 부문 기사 크롤링]
# 중앙일보 코로나 후
import excluded as ex
import requests
from bs4 import BeautifulSoup
from collections import Counter
import re
import numpy as np
import matplotlib.pyplot as plt
from konlpy.tag import Okt
plt.rc("font", family="Malgun Gothic")
base_url = "https://www.joongang.co.kr/money/general?startDate=2020-04-01&endDate=2020-04-30&page={}" #객관적인 자료 확보를 위해 아무 검색 키워드 없이 정치 면 크롤링 (정치일반)
html_urls = []
for page in range(1,44):
url = base_url.format(page)
html_urls.append(url)
# 기사 미리보기 페이지에서 추출한 기사 목록 저장을 위한 빈 배열
urls = []
for url in html_urls:
response = requests.get(url)
# HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# URL 추출
cards = soup.select(
'div#wrapper>main#container>section.contents>div.row>section.chain_wrap.col_lg9>ul.story_list>li.card>div.card_body>h2.headline>a')
for card in cards:
article_url = card['href']
urls.append(article_url)
#####################
# 전체 단어 빈도를 저장할 Counter 객체
total_word_counts = Counter()
okt = Okt()
for url in urls:
response = requests.get(url)
# HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 기사 본문 선택
article_body_element = soup.select(
'div#wrapper>main#container>section.contents>article.article>div#article_body.article_body.fs3>p')
if article_body_element:
# 특수 문자 제거 및 소문자 변환
article_body = re.sub(r"[^\w\s]", "", str(article_body_element)).lower()
# 명사 추출
nouns = okt.nouns(article_body)
ex.excluded_words.extend(["코로나", "코로나바이러스"])
# 단어 빈도 분석
word_counts = Counter(word for word in nouns if word not in ex.excluded_words)
# 단어 빈도를 전체 빈도에 누적
total_word_counts += word_counts
# 가장 많이 등장한 단어 50개 추출
top_words = total_word_counts.most_common(50)
# 시각화를 위한 데이터 준비
labels, counts = zip(*top_words)
x = np.arange(len(labels))
# 막대 그래프 그리기
plt.bar(x, counts, align="center")
plt.xticks(x, labels)
plt.xlabel("단어")
plt.ylabel("빈도수")
plt.title("중앙일보 코로나19 <1달 전 - 정치> 관련 기사 단어 빈도수 분석")
plt.show()
# 결과 출력
print("중앙일보 코로나19 재난지원금 지급 <1달 전 - 정치> 관련 기사 중 가장 많이 등장한 단어 50개:")
for word, count in top_words:
print(f"{word}: {count}")
# 사용자 입력 대기
input("Press Enter to exit...")[중앙일보 금융위기 1달 전 경제 부문 기사 크롤링]
# 중앙일보 금융위기 후 사회
import excluded as ex
import requests
from bs4 import BeautifulSoup
from collections import Counter
import re
import numpy as np
import matplotlib.pyplot as plt
from konlpy.tag import Okt
plt.rc("font", family="Malgun Gothic")
base_url = "https://www.joongang.co.kr/money/general?startDate=2008-08-14&endDate=2008-09-13&page={}" #객관적인 자료 확보를 위해 아무 검색 키워드 없이 정치 면 크롤링 (정치일반)
html_urls = []
for page in range(1,20):
url = base_url.format(page)
html_urls.append(url)
# 기사 미리보기 페이지에서 추출한 기사 목록 저장을 위한 빈 배열
urls = []
for url in html_urls:
response = requests.get(url)
# HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# URL 추출
cards = soup.select(
'div#wrapper>main#container>section.contents>div.row>section.chain_wrap.col_lg9>ul.story_list>li.card>div.card_body>h2.headline>a')
for card in cards:
article_url = card['href']
urls.append(article_url)
#####################
# 전체 단어 빈도를 저장할 Counter 객체
total_word_counts = Counter()
okt = Okt()
for url in urls:
response = requests.get(url)
# HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 기사 본문 선택
article_body_element = soup.select(
'div#wrapper>main#container>section.contents>article.article>div#article_body.article_body.fs3>p')
if article_body_element:
# 특수 문자 제거 및 소문자 변환
article_body = re.sub(r"[^\w\s]", "", str(article_body_element)).lower()
# 명사 추출
nouns = okt.nouns(article_body)
ex.excluded_words.extend(["금융위기"])
# 단어 빈도 분석
word_counts = Counter(word for word in nouns if word not in ex.excluded_words)
# 단어 빈도를 전체 빈도에 누적
total_word_counts += word_counts
# 가장 많이 등장한 단어 50개 추출
top_words = total_word_counts.most_common(50)
# 시각화를 위한 데이터 준비
labels, counts = zip(*top_words)
x = np.arange(len(labels))
# 막대 그래프 그리기
plt.bar(x, counts, align="center")
plt.xticks(x, labels)
plt.xlabel("단어")
plt.ylabel("빈도수")
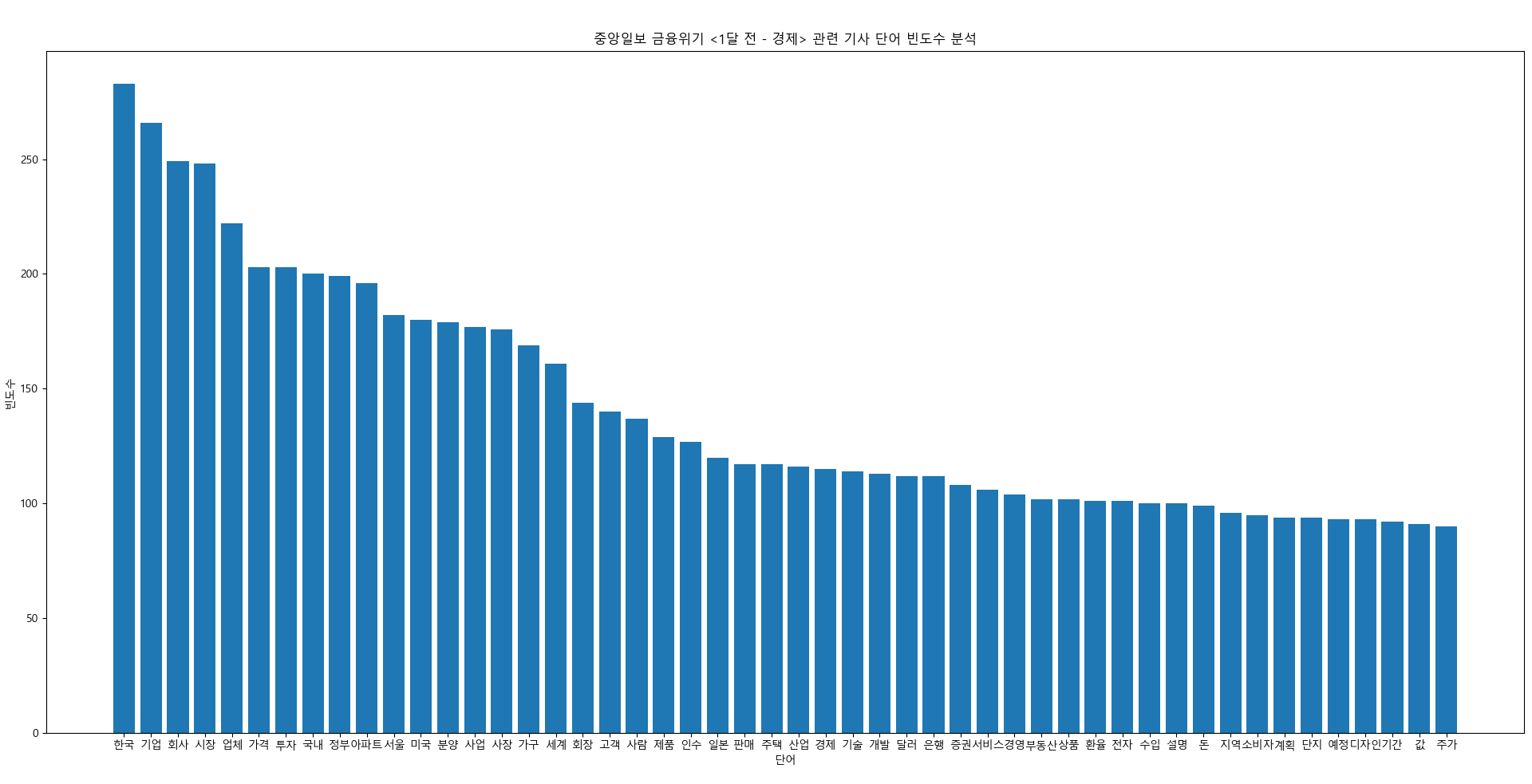
plt.title("중앙일보 금융위기 <1달 전 - 경제> 관련 기사 단어 빈도수 분석")
plt.show()
# 결과 출력
print("중앙일보 금융위기 <1달 전 - 경제> 관련 기사 중 가장 많이 등장한 단어 50개:")
for word, count in top_words:
print(f"{word}: {count}")
# 사용자 입력 대기
input("Press Enter to exit...")위와 동일한 매커니즘으로 정치, 사회, 경제 부문 따로 크롤링







'AIH 학부연구생 > 23_1 연구 논문' 카테고리의 다른 글
| 2023-1 학부연구생 연구 최종 보고서 (0) | 2023.08.24 |
|---|---|
| 5월 22일 주제 발표 (0) | 2023.05.22 |
| 연구 계획서 (최초 기획안 ver.) (0) | 2023.04.01 |
'AIH 학부연구생/23_1 연구 논문' Related Articles
more
