
archive
Crayon: Customized On-Device LLM viaInstant Adapter Blending and Edge-Server Hybrid Inference 본문
Crayon: Customized On-Device LLM viaInstant Adapter Blending and Edge-Server Hybrid Inference
안정민 2025. 3. 29. 16:08리뷰 논문 :
https://aclanthology.org/2024.acl-long.204.pdf
1. Introduction
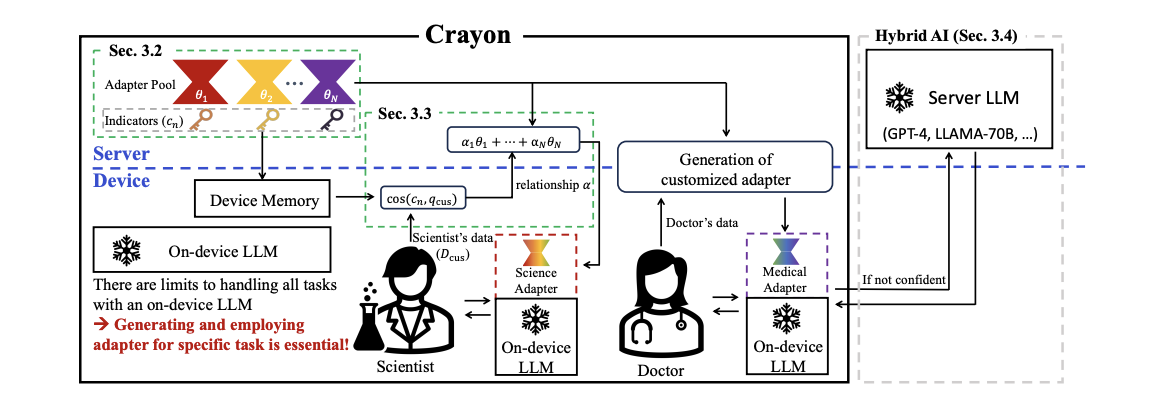
최근 LLM 의 핵심적인 동향 = 고도화된 맞춤형 LLM (customized LLM)
→ 사용자 요청에 특화된 작업을 수행할 줄 아는 맞춤형 LLM의 수요가 늘어나고 있음
[문제점]
- LLM의 방대한 크기는 모든 맞춤형 LLM을 서버에 보관하기 어렵게 함
- 사용자 맞춤 개인화 == 개인정보 문제 발생이 불가피
→점점 초점이 디바이스 내 LLM으로 이동 (개인정보 보호 및 개인에게 필요한 LLM만 보관)
[문제점 2]
- 엣지 디바이스의 제한된 연산 능력 → 서버수준의 대형 모델을 그대로 사용하는 것은 비현실적
→ 이 문제를 해결하기 위해 few-shot 및 in-context learning (COT) , RAG 등의 방법론이 제안
→ 이러한 프롬프트 기반 접근법은, 프롬프트가 길고 복잡할 수록 추론 비용이 증가한다는 본질적인 문제가 존재
→ 따라서 엣지 디바이스가 가지는 제한된 연산 능력을 보완하지 못 한다
→ 파인튜닝의 경우 시간이 많이 들고 개인화된 데이터가 소량이라는 점, 연산능력이 여전히 보완 불가능하다는 점이 문제점으로 남는다
| Q. 디바이스 내 학습 없이 단순히 LLM을 맞춤화 할 수 없는 것일까? A. Crayon 제안 |
Crayon
어댑터 풀 (adapter pool) 이라고 불리는 기본 어댑터 집합에서
실시간으로 블렌딩 된 하나의 맞춤 어댑터를 통해
디바이스 내의 LLM 을 커스터마이징 하는 방법론을 제안
[논문의 목표]
1. 다양한 사용자 요구를 다루기 위해 서로 다른 데이터를 활용해, 서로 다른 기본 어댑터 여러 개를 제작한다
2. 그리고 서로 다른 어댑터를 블렌딩할 때 추가 학습 비용이 들지 않는다
3. 맞춤형 모델이 다루기 힘든 예외적인 쿼리는 서버에서 처리 → 디바이스-서버 하이브리드 추론 전략
4. LLM 커스터마이징 벤치마크 제시
2. Problem Set-up
(1) Defining & processing customized task (사용자 맞춤형 작업 정의 및 처리)
기존 few-shot 학습처럼 긴 프롬프트를 사용하는 대신,
사용자의 작업에 대해 맞춤형 어댑터를 서버에서 생성하고 디바이스에 배포
→ 추론 비용을 줄여주는 효과
→ 데이터 프라이버시도 보장하여 온디바이스 상황에 적합
(2) Baseline LLM (기준 LLM 선정)
auto-regressive 언어 모델에서는 GPT, LLaMA, Mistral, Falcon 등 대부분 인기있는 모델이 decoder only 아키텍처를 채택
따라서 본 연구에서는 가장 작은 LLaMA-7B를 디바이스 내 LLM의 기준 모델로 선정
→서버 수준의 대형 모델은 아니지만
→엣지 디바이스에 가장 적절한 크기
(3) Adapter for customized LLM (맞춤형 LLM을 위한 어댑터 설계)
LLM 어댑터로 채택 → LoRA (Low-rank Adaptation)
LoRA 학습은 디바이스 내에서 수행되는 것이 아닌 서버에서 훈련
즉, 서버에서 훈련 데이터셋 Dtr을 기반으로 N개의 기본 LoRA 들을 학습하여 LoRA 풀 (LoRA pool)을 구성
그리고 이들을 조합하여 사용자 맞춤형 목표 작업 Dc에 대한 즉석 LLM 커스터마이징을 수행하며
디바이스 내의 추가학습은 필요 없게 된다
(4) Device-server hybrid inference (디바이스-서버 하이브리드 추론)
디바이스 내 모델이 아무리 사용자 지정 작업에 잘 맞추어져 있다고 하더라도
디바이스 LLM 과 서버 수준의 LLM 간에는 불가피한 성능 격차가 존재할 수밖에 없게 된다
*입력이 목표 작업 범위를 벗어날 경우* 디바이스 내 LLM의 성능 저하는 더 심해진다
→ 디바이스-서버 하이브리드 추론 전략 고안
→ 디바이스 내 LLM 출력의 신뢰도가 낮은 경우, 해당 출력은 서버의 대형 모델이 생성한 결과로 대체
→ 서버 LLM의 빈번한 사용을 줄이기 위해, 디바이스 내부 LLM의 출력 신뢰도 판단하는 로직을 개발함
3. Methodology
(1) Overall Framework (Crayon의 전체 구조)
[구성요소]
| Dtr | 다양한 작업들로 구성된 학습데이터 |
| Φ₀ | 커스터마이징 이전의 초기 가중치 |
| M_Φ₀ | 초기 가중치를 가지는 기준 LLM |
 |
서버에서 기본 LoRA 학습 → 서로 다른 특성과 지식을 갖도록 공동 학습 → 각 LoRA 에 할당되는 지시자 (indicator) 도 함께 학습 LoRA들은 LoRA pool 로서 서버에 저장됨 |
| c_n | LoRA n에 할당되는 지시자 indicator indicator 들은 디바이스에 저장됨 |
이후 소규모 맞춤형 데이터셋 Dc 가 사용자로부터 주어지면,
디바이스 상에서 indicator 들과 Dc 간의 유사도를 계산하여 LoRA pool 과 Dc의 관계를 파악
이 유사도는 서버로 전송되며, 커스터마이징된 LoRA 를 구성하기 위한 기본 LoRA 들의 가중치를 결정하는데 활용
이 맞춤형 LoRA 는 최종적으로 사용자 디바이스에 배포
Dc 자체가 서버로 전송되지 않고 indicator 들과의 유사도만 업로드 됨
→ 개인정보 친화적 !
(2) Crayon : LoRA Pool Construction (LoRA pool 구축 과정)

[STEP 1 : indicator 설정]
Dtr의 모든 데이터 x에 대해 중간 임베딩은 다음의 식과 같이 얻게 된다

클러스터링 이전 PCA를 통한 임베딩 차원 축소 → 노이즈를 줄이고 주요 특징에 집중
Dtr의 텍스트에는 별도의 태스크 레이블이 없기 때문에 q_x 를 기반으로 비지도 k-mean 클러스터링 (k = N) 을 적용
k-means 로부터 나온 N개의 중심점 c_n을 각 base LoRA 에 할당하여 이를 indicator로 사용
→ 즉, 클러스터링을 통해 선별된 각 클러스터의 가장 대표성을 띄는 중간 임베딩을
→ 각 클러스터의 데이터로 학습될 LoRA의 indicator로 활용
[STEP 2 : Base LoRA 학습]
학습으로 활용될 입력데이터 x ∈ Dtr 에 대해 q_x 추출
그 후 q_x 와 각 base LoRA indicator 간의 코사인 유사도 계산
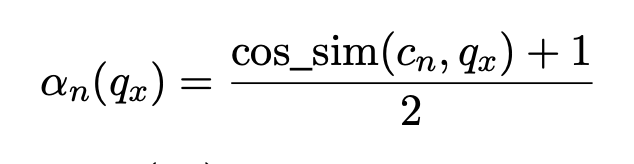
그런 다음 입력 x에 맞는 LoRA l_Θ 를 얻기 위해 각 base LoRA를 가중치로 하여 선형결합
코사인 유사도 기반의 가중치 업데이트 파라미터가 완성이 됨
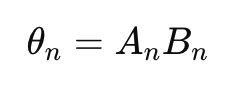
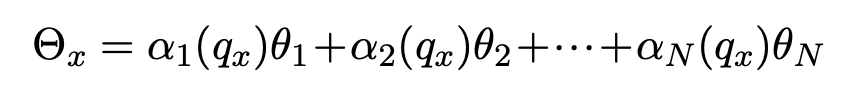
즉, 각 입력 x에 대해 알맞은 LoRA 할당을 위해 코사인 거리를 가중치로 활용
→ 코사인 유사도가 높을 수록 높은 가중치 할당
→ 많은 N개의 LoRA 중 가장 유사한 task를 수행할 LoRA에 더 높은 가중치 할당
기존 LoRA의 방법대로 base LLM의 가중치는 고정하고 LoRA들만 학습

이를 기반으로 위와 같이 LLM을 업데이트
[요약]
| 입력 | 기준 LLM, LoRA들, 학습데이터 Dtr |
| 1단계 | 중간 임베딩 추출 |
| 2단계 | k-means 클러스터의 중심으로 indicator 생성 |
| 3단계 | 각 LoRA 와의 유사도 계산 (코사인 유사도) → 유사도와 결합된 LoRA θₓ 생성 |
| 4단계 | θₓ 기반으로 base LoRA 가중치 학습 |
| 결과 | 다양한 지식을 내포한 base LoRA pool 완성 |
(3) Crayon: Generation of Customized LoRA (맞춤형 LoRA 생성)

사용자가 맞춤형 작업을 설명하는 사용자 데이터 Dc를 제공한다면
LoRA pool에서 즉시 맞춤형 LoRA를 생성해낼 수 있다는 것이 이 논문의 아이디어이다

이를 위해 먼저 Dc 내의 쿼리 임베딩을 평균을 내어
customized task를 대표하는 사용자 임베딩 qc를 디바이스에서 계산
그 다음 위 방정식을 다시 가지고 와서
qc와 base LoRA indicator cn 간의 코사인 유사도를 통해 조합 가중치 α_i_c 를 계산
→ dc 자체는 서버에 보내지 않고 α_i_c 들만 업로드하므로 사용자 개인정보를 보호할 수 있음

서버에서는 base LoRA 가중치
| 입력 | base LoRA들, indicator들, 기준 LLM, 사용자 맞춤 데이터 Dc |
| 디바이스 1단계 | Dc 에서 임베딩 추출 |
| 디바이스 2단계 | 평균 임베딩 qc 계산 → 사용자 customized task 대표하는 값 |
| 디바이스 3단계 | 각 indicator 와의 코사인 유사도 → 계산 |
| 서버 단계 | LoRA 풀의 A_i, B_i 와 αic로 weighted sum → θ^ 생성 |
| 결과 | customized LoRA 완성 후 디바이스에 배포 |
(4) Device-Server Hybrid Inference (디바이스-서버 하이브리드 추론)
사용자가 맞춤형 작업 범위를 벗어난 질문을 할 수 있음
또한 맞춤형 작업에 속하는 질문이더라도 온디바이스 모델은 크기가 작아 성능이 base 모델과 차이가 큼
→ 계산 비용이 높은 서버 기반 대형 LLM (LLaMA-30B 채택) 을 간헐적으로 사용
→ 커스터마이징은 되어있지 않으나 일반적인 성능이 더 뛰어남
[STEP 1 : 서버 라우팅 판단]
입력 쿼리 x를 서버로 보낼지 결정할 때에는 서버 LLM 인 MΦs 를 직접 활용할 수 없음
대신 에 대해 서버 LLM의 출력을 미리 계산하여 프로토타입 집합 S 를 만듦
이 S는 customized LoRA θ^ 와 함께 서버에서 디바이스로 전송
[STEP 2 : 라우팅 점수 계산]
실제 출력과 S를 비교
디바이스 내에서 실제 출력과 와 S 간 코사인 유사도를 평균 내어 라우팅 점수 r_를 계산

[STEP 3 : 최종 라우팅 결정]
라우팅 임계값 r_th는 경험적으로 설정됩니다.
이면 x를 서버 LLM으로 라우팅하고, 그렇지 않으면 on-device 출력 결과를 그대로 사용
간단한 예시는 다음과 같다
위 전 과정을 더 쉽게 이해하기 위해
예시의 경우 GPT-4o 를 활용하여 생성하였음





4. Experiment
(1) On-device Customization Benchmark
벤치마크 데이터셋 선정 : QA 데이터셋과 작업일반화 검증 데이터셋 선정
세가지 벤치마크 QA 데이터셋 선택 (질의응답 QA 데이터셋 → LLM 평가에 널리 활용됨)
- SIQA : 사람들의 행동 및 사회적 의미에 대한 추론 데이터셋
- MedMCQA : 의학 입시 문제 데이터셋
- Openbook QA : 사람의 주제 이해도 평가 오픈북 시험 데이터셋
작업 일반화를 검증하기 위해, MMLU 데이터셋 선정
→ STEM, 인문학, 사회과학 등을 포함하는 57개 과목을 다룬 데이터셋
→ 이를 57명의 각기 다른 사용자가 자신만의 맞춤형 작업을 수행한다고 가정하고 맞춤형 작업 구성
→ 이를 바탕으로 정확도 (Acc) 기준으로 맞춤화 결과를 정량적으로 평가 가능
→ 모든 사용자의 맞춤형 데이터셋 크기를 10으로 설정하였음
(2) Main Result


'ML_AI > 논문 리뷰' 카테고리의 다른 글
| [Model Merging]TIES-MERGING: Resolving Interference When Merging Models (0) | 2025.04.30 |
|---|---|
| [Model Merging] Editing Models with Task Arithmetic (0) | 2025.04.29 |
| [2월 NLP 기초 논문 스터디] LoRA (PEFT) (0) | 2025.03.02 |
| [2월 NLP 기초 논문 스터디] BERT (Pretraining) (0) | 2025.03.02 |
| [2월 NLP 기초 논문 스터디] Dependency Parsing (0) | 2025.02.09 |

