
archive
[Model Merging] Editing Models with Task Arithmetic 본문
https://arxiv.org/pdf/2212.04089
model merging 관련 논문
1. Introduction
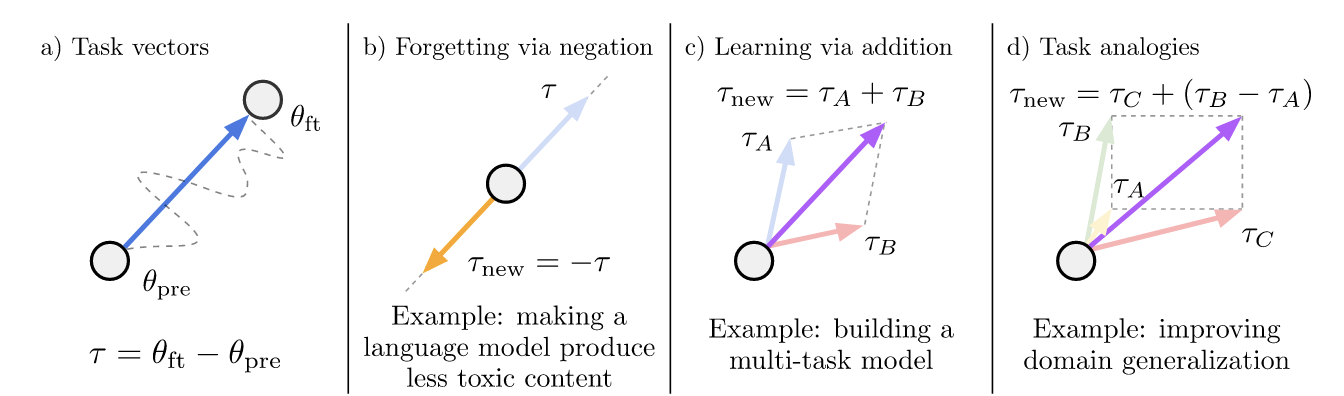
pretrained model 을 대상으로 후속적인 튜닝 작업을 수행하며 모델을 정교하게 손봄
task vector -> 후속작업의 새로운 패러다임을 제공함
(task vector) = (finetuned weight) - (pretrained weight)
위와 같은 공식으로 구해진 task vector 을 활용한 간단한 산술 연산 (task arithmetic)을 통해 다양한 모델을 편집 가능
(1) negating : 바람직하지 않은 동작 제거, negated task vector == −(original task vector)
(2) adding : 더 나은 멀티태스킹 모델로 진화 및 단일작업 성능 향상
(3) analogy relationship : 유추관계, 작업벡터가 결합하여 데이터가 부족한 작업의 성능 향상
task arithmetic을 통해
추가 데이터 혹은 추가 훈련의 필요 없이 오픈소스 모델에서 지식을 재사용 혹은 merging이 가능하다
비용적인 측면에서 아주 효과적이고 효율적!
1.1 Forgetting via negation
toxic data 로 파인튜닝된 모델이 있음 -> 이 모델은 유해 텍스트 생성에 전문화됨
이 모델의 task vector을 반전시킴
= 유해 텍스트 생성 비율이 줄어들었음
= 텍스트 생성의 자연스러움은 그대로 유지되었음
즉, task vector는 단순히 생성된 벡터가 아니라
(post trained weight) - (pre trained weight) 의 계산으로 생성된 벡터이므로
negate 연산 수행 시,
특정 작업에 대한 역효과를 낼 수 있음과 동시에 general task 성능에 대해서는 영향 없이 유지가 가능하게 되는 것이다
== selective forgetting 이 가능함
원래 pretrained 모델이 가지던 값으로 회귀 !
1.2 Learning via addition
여러 개의 task vector를 합하여 하나의 unified 모델을 만들 수 있다.
이 unified 모델의 경우 개별 모델 사용보다 비슷하거나 더 좋은 성능을 낼 수 있다는 것을 확인
=> 즉 하나의 모델을 각각 다른 task 에 특화되도록 훈련 후 합침
** gpt 질문 ) embedding 방식이나 모델 종류(텍스트, 이미지 등) 가 다른 모델끼리의 addition이 가능한가?
-> 어려움, 그러나 동시 학습을 진행한 CLIP의 경우에는 가능할 수 있음, 성능은 미비
또한 task A + task B 의 task vector을 통해 목표 task C 의 성능 향상도 기대할 수 있음
=> task vector addition은 단순한 특정 task에 대한 정보 뿐만 아니라 general task에 대한 정보도 담고 있기 때문
1.3 Task Analogies
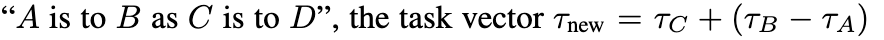
"A 작업을 B 작업으로 전환하는 것" == "C 작업을 D 작업으로 전환하는 것"
의 관계를 설정하였을 때,
A, B, C task에 대한 데이터만 있다면 , D task에 대한 훈련데이터가 거의 없거나 아예 없는 상황에서도 성능 도출이 가능
일반적으로는 D에 대한 labeled 데이터가 반드시 있어야 훈련이 가능,
zero-shot task generalization 성능을 도출할 수 있게 됨
2. Task vectors

τ_t 벡터는 element wise subtraction을 통해 정의된다
즉, task vector는
해당 task를 잘 수행하기 위해 가중치를 '어떻게' 이동시켰는가를 나타내는 방향벡터
이 벡터를 통해 모델 구조를 고치지 않고 추가적인 model editing 이 가능함
task vector을 깔끔하게 정의한 뒤, 조합할 수 있기 때문
(따라서 새로운 파라미터가 생기거나 모델 구조 자체의 변화가 생기는 것에 대해서는 추가 연구 과제로 남김)
| 📚 새로운 파라미터가 추가된 모델 병합 관련 주요 논문 WEMoE: Weight-Ensembling Mixture of Experts for Merging Pretrained Models (Tang et al., 2024) 🔗 arXiv:2403.17881 MaTS: Matching Models in Task Parameter Subspaces for Model Merging (Tam et al., 2024) 🔗 arXiv:2402.04048 PCB-Merging: Balancing Parameter Competition for Effective Model Merging (Chung et al., 2024) 🔗 arXiv:2404.05549 |
3. Forgetting via Negation
forgetting / unlearning : pretrained 모델에서 원치 않는 편향을 완화하는 것에 도움
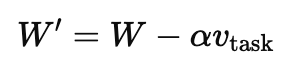
그러나 이러한 개입은 편집 밖의 범위의 task 성능에는 영향을 주어서는 안 됨
-> 해당 논문에서는 control task의 정확도도 함께 측정
3.2 Text Generation
목표 : GPT-2 모델이 생성하는 유해 텍스트의 양을 줄임
데이터셋 : Civil Comments 데이터셋 중 toxicity 점수가 0.8을 초과하는 데이터로 파인튜닝
방법론 : 파인튜닝한 모델의 가중치를 활용해 태스크 벡터 생성 뒤 태스크 벡터를 부정
비교군 : (1) gradient ascent를 통한 가중치 조정, (2) 무작위 태스크 벡터를 사용하여 가중치 조정, (3) non-toxic 데이터로 파인튜닝
이와 같은 방법으로 모델 제작 후,
모델이 생성한 1000개의 샘플의 유해성 측정 (Detoxify 활용)
control task : WikiText-103 데이터셋에 대한 언어모델의 perplexity
(perplexity : 문장 예측 시 모델이 얼마나 다양한 단어를 후보로 고려하는가, 낮으면 문장 잘 예측하는 지표임)
[주요 결과]
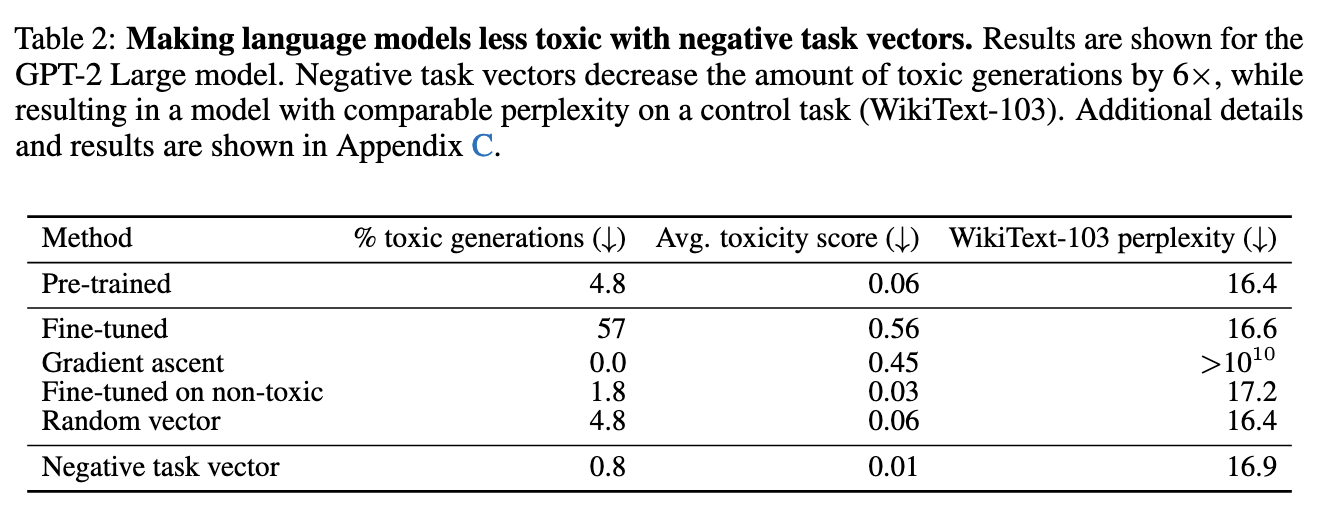
| negating task vector | 유해 텍스트 비율을 4.8% -> 0.8% 로 감소시킴 언어모델 퍼플렉시티 (control task) 지수의 변화는 거의 없음 |
| gradient ascent | 유해성은 줄었으나 control task의 성능을 수용 불가 수준으로 심각하게 저하 |
| non-toxic data finetuning | negating task vector 방법보다 유해성 감소 및 control task 유지 모두에서 성능이 떨어짐 |
| random vector | 별 다른 영향이 없었음 |
4. Learning via Addition

여러 작업을 수행하는 멀티태스크 모델을 구축하거나, 단일 작업 모델의 성능 개선을 도모 가능
추가적인 학습 데이터 접근 및 학습 없이 지식 재사용 및 전이 가능
4.1 Natural Language Processing
태스크 벡터를 추가 => 멀티태스크 성능 + 단일태스크 성능 모두 향상

5. Task Analogy
“A is to B as C is to D” 형태의 task analogy
처음 세 개의 작업으로부터 얻은 벡터를 활용한 태스크 연산
-> 작업 D에 대한 데이터가 거의 없거나 전혀 없는 경우에도 작업 D의 성능을 향상시킬 수 있음
(1) 라벨링 관점에서의 효율
(2) 데이터 희귀현상 관점에서의 효율
5.1 Domain Generalization
** 도메인 일반화 : 학습할 때 본 적 없는 도메인 (데이터 분포)에서도 모델이 졸은 성능을 유지하는 것
(레이블여부)
데이터 수집 난이도 : 비라벨데이터 <<<<< 레이블 된 데이터
따라서 target task에 대한 라벨이 없는 경우에도 태스크 아날로지를 통해 정확도 향상이 가능하다
구분 : (1) 보조 작업 auxiliary task : 이미 라벨 존재 , (2) 비지도 학습 목표 unsupervised learning object
(1) 과 (2) 를 결합하여 사용

만약 아마존 데이터를 이용해서 감정 분석 보조 작업 (라벨링이 완료됨) 을 마쳐둔 상태이고,
yelp는 언어 모델링 태스크 벡터라면 여기에 감정분석 데이터셋을 투입하거나 라벨링을 추가적으로 진행하지 않아도
yelp에 대한 감정 분석 태스크 벡터를 형성할 수 있음
두 개의 scaling coefficient
=> 감정 분석 벡터와 언어 모델링 벡터 간 중요도가 다르기 떄문에 각각 다른 가중치 (스케일링 계수)를 적용
=> 실험적으로 감정분석벡터를 좀 더 강하게 주는 것이 성능이 좋았음
5.2 Subpopulations with little data
특정 데이터 하위 집단 (subpopulation)에는 본질적인 희소성이 존재
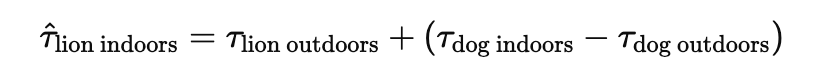
실내에 있는 사자 데이터 <<< 야외 사자 데이터, 일반적인 개 이미지
=> 보다 풍부한 데이터를 가진 다른 집단과 - 하위 집단의 아날로지가 이루어진다면 task analogy 적용 가능
6. Discussion
6.1 Similarity between task vectors
서로 다른 작업들의 테스트 벡터 간 코사인 유사도 탐구
=> 여러 모델을 하나의 멀티태스크 모델로 벡터 덧셈 방식으로 통합할 수 있는 이유 탐구
=> Q. 왜 서로 다른 작업의 태스크 벡터를 더했을 때 간섭이 적을까? (interference is minimal)
**간섭 : 여러 작업을 하나의 모델 안에서 합치려고 할 때 하나의 작업을 잘 하려고 조정한 것이 다른 작업의 성능을 망치는 것
즉, 한 작업을 모델에 추가해도 다른 작업의 성능이나 방향성이 거의 방해받지 않는 것
즉, 태스크 벡터가 각각 독립적으로 잘 유지된다는 것
1. 거의 직교 (orthogonal) : 작업이 다르면 벡터는 보통 방향이 크게 다름 (cosine similarity ≈ 0)
2. 비슷한 작업은 코사인 유사도가 높음 예) MNIST ↔ SVHN ↔ GTSRB (숫자 인식)
따라서 여러 작업을 합칠 때 충돌이 적고 서로 강화
더해서, 구조적으로 비슷한 다른 작업에서도 성능 향상 => MNIST 태스크 벡터를 적용 시 SVHN (거리 사진 속 숫자) 성능 향상
즉, 전이 효과 가능
[수학적 증명]
두 task vector가 직교라면 v1⋅v2 == 0 (내적이 0, 즉 방향이 완전히 다름)
v1을 추가해도 v2에 대한 영향을 거의 주지 않게 됨
"서로 다른 방향을 보고 있는 두 사람에게,
한쪽 사람을 1미터 앞으로 이동시켜도,
다른 쪽 사람이 보는 방향이나 위치에는 아무런 영향이 없는 것."
6.2 The impact of the learning rate
** 여기서의 learning rate : pretrained 모델을 파인튜닝하는 과정에서 사용되는 학습률
학습률이 모델 편집 (task vector 적용) 성능에 어떤 영향을 주는가?
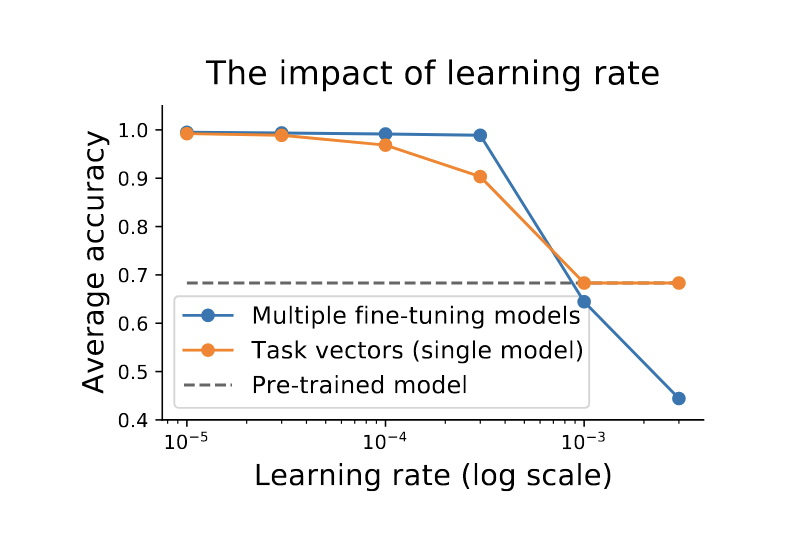
task vector 형성을 위해 finetuning 시 학습률을 높이면 정확도가 감소
=> 모델이 pretrained 모델과 너무 다른 위치로 이동해서 task vector가 부자연스럽게 형성될 수 있음
=> 개별 모델 파인튜닝에서 학습률 민감도 <<< task vector에서 학습률 민감도
따라서 task vector addition 을 할 때 작은 학습률이 필수적이다
** 개별 파인튜닝을 할 때에는 학습률이 커도 어느정도 괜찮을 수 있음 (모델 파인튜닝만 잘 되면 되니까)
**그러나 task vector라는 추가 가공이 필요할 시에는 처음부터 학습률을 작게 잡는 것이 중요하다
6.3 The evolution of task vectors throughout fine-tuning
보통 task vector의 경우 finetuning이 끝난 모델을 기준으로 만듦
=> 실험해보니 finetuning 중간 과정의 모델에서 뽑아낸 task vector 또한 최종 task vector 방향과 꽤 빨리 비슷해짐
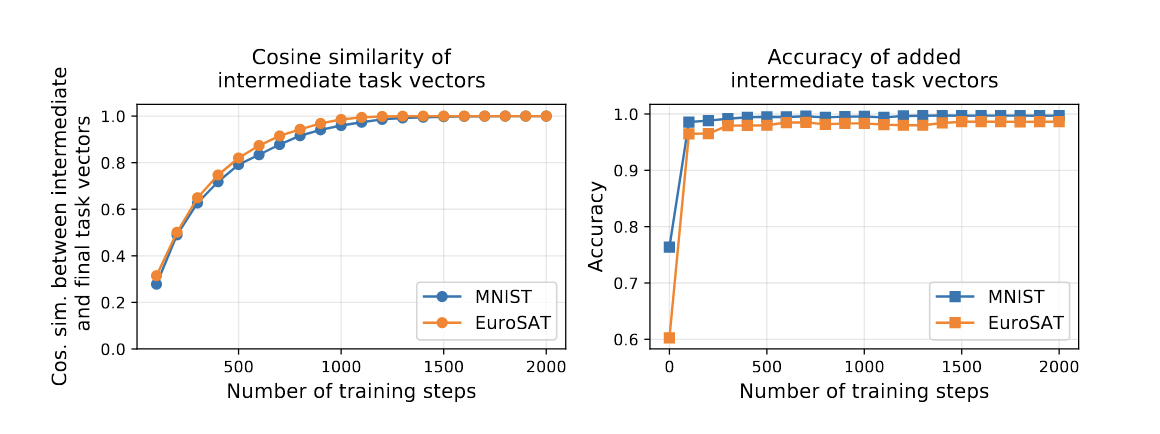
즉, task vector을 생성하기 위해 finetuning을 꼭 오래 할 필요가 없다
중간 단계에서도 충분히 좋은 task vector을 생성해낼 수 있기 때문에,
계산량을 줄이고 효율적으로 task vecotr을 만들어내는 것이 가능하다
6.4 Limitation
1. 모델의 아키텍쳐가 동일할 때에만 task vector을 사용할 수 있음
=> task vector는 모델 파라미터에 대해 element-wise 연산을 수행하기 때문
=> (layer 수, shape, tensor 크기 등이 다르면 불가능)
2. 같은 pretrained 모델이어야 함
pre-trained 시작점이 다르면, weight space가 다르기 때문에 task vector 적용이 부자연
즉, 같은 구조, 같은 초기화에서 나온 모델들끼리만 잘 동작한다


