

archive
[3주차 복습] 결측치, 누락값, 이상치 (1) 본문
1. 결측치와 누락값, 그리고 이상치
:결측치와 누락값이 공통적으로 이야기하는 것은 값이 없다는 것 (NA, NaN 데이터에 보이는 것)
:누락값은 휴먼 에러로 인한 누락값, 따라서 어떤 이유로 누락이 되었는지 확인이 힐요
:결측지는 실제 Na값이지만 정말 Na 값인지 확인이 필요, 따라서 결측치가 순수하게 결측치의 의미인가 아니면 na값 자체가 값일 수 있는 것
:결측치 처리하는 방법
① 가장 간단한 것은 버리고 날리는 것 -> 결측치를 날리는 기준은? 결측치가 전체 비중의 1%가 안 되면 쉽게 날리나, 절대값에 따라 달라질 수 있다.
② 결측치가 상당한 비중을 차지하는 경우? -> 이걸 다 날리게 된다면 머신에게 학습할 데이터 양이 줄어드는 것이므로 성능에 영향을 미칠 수 있게 되는 것이므로 결측치를 최대한 채워서 메꾸는 형식을 생각한다.
③ 너무 데이터가 다 결측치이면 그것은 날려도 상관이 없음 -> 80~90% 다 결측치 칼럼이면 비즈니스적인 이해관계를 보고 도메인 지식을 이용해 날려야 한다.
:결론적으로 결측치는 단순히 생각할 것이 아님 / 도메인과 통계적인 다방면적인 고민으로 해결해야 할 문제
:결측치를 나타내는 용어
-완전 무작위 결측치 : MCAR (Missing Completely at Random) 어떤 인간의 편향이나 기계의 결함이 아니라 완전 무작위 랜덤한 결측치
- 무작위 결측 MAR(Missing at Random) : 어떤 상황으로 인해서 발생하는 경우
- 비무작위 결측 NMAR(Missing at Not Random) : 결측값인데 정말 na가 하나의 특성이 될 수 있는 것, na값 자체가 값일 수 있는 것
① isna() 함수 : isna 메서드는 DataFrame내의 결측값을 확인해서 bool형식으로 반환하는 메서드, isna의 경우 결측값이면 True 반환, 정상값이면 False반환
②missingno 패키지 : 결측 데이터들을 파악하는데 직관적인 도움을 주는 패키지로, 이 중 matrix() 메서드는 변수로 전달한 데이터셋에 대한 결측치를 매트릭스로 시각화해 주는 역할을 한다.
: msno.matrix(df=df_train.iloc[:, :], color=(0.1, 0.6, 0.8)) 의 예제 코드에서는 df_train으로 지정한 데이터셋에 대하여 color 파라미터를 지정하여 RGB를 지정해주는 것까지 수행이 가능하다.
실행결과: 아래의 매트릭스가 출력되는데 흰색으로 표현된 빈칸들이 결측치이다.

: missingno 패키지에서 matrix() 메소드 말고도 bar() 메소드를 이용할 수 있는데, 동일하게 매개변수로 데이터셋을 전달하면 바 형태의 차트로 시각화를 해 준다. 전체값에서 결측치를 제외한 실질적인 값을 바 그래프의 형태로 나타내어주며, 위의 빈 공간만큼 결측치가 있다는 것을 시각화를 통해 확인이 가능하다.
실행결과:
2. 결측치 처리 방법
-결측치 날리기, 제외하고 진행하기, 평균/중위값 등의 어떤 특정 통계 값으로 대체하는 것, 보간법(interpolation)...
-수업에는 보간법에 집중 (선형보간법, spline 보간법, 시계열보간법)
** loc() 과 iloc()
-loc() : 데이터 프레임의 행이나 컬럼에 label이나 boolean array로 접근하는 것, location의 약자로 인간이 읽을 수 있는 label값으로 데이터에 접근하는 것이다.
-iloc() : 데이터 프레임의 행이나 컬럼에 인덱스 값으로 접근하는 것, integer location의 약자로 컴퓨터가 읽을 수 있는 indexing 값으로 데이터에 접근하는 것이다.
** to_frame() : 통계값인 데이터 시리즈를 데이터프레임으로 바꿔주는 함수, 딱히 설정할 파라미터는 없고 데이터 시리즈가 담긴 변수 뒤에 도트 연산자를 사용하여 붙여주고 실행하기만 하면 된다
:다만, 이미 데이터 프레임인 정보가 담긴 변수 뒤에 to_frame()을 실행하면 오류가 발생한다.
-dropna() 메서드 : 결측치를 날리는 방법
ebola=dfe.iloc[0:15,0:5]
ebola.dropna()
- fillna(method='') : DataFrame에서 결측값을 원하는 값으로 변경하는 메서드
ebola['Cases_Liberia'].fillna(7960.111111111111).to_frame()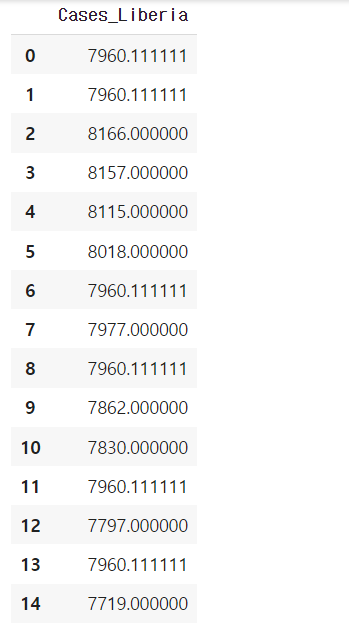
: fillna() 메소드의 매개변수로 직접 결측값을 대체할 수를 전달할 수도 있고, 결측치를 치환시킬 메소드를 전달하는 것도 가능하다, 그 메소드 중 두 가지가 바로 ffill 과 bfill 이다.
-ffill: 누락값이 나타나기 전의 값으로 누락값을 변경, 즉 method인수에 ffill을 입력할 경우 결측값이 바로 위값과 동일하게 설정
-bfill:누락값이 나타나나 이후의 첫번째 값으로 앞쪽의 누락값을 변경, 즉 method인수에 bfill을 입력할 경우 결측값이 바로 아래값과 동일하게 설정
3. 보간법
-문법 : interpolate(method=' ')
-누락값 사이의 값을(누락값 바로 위와 바로 아래의 값 두 개) 평균으로 대체해서 만든다
ebola['Cases_Liberia'].interpolate().to_frame()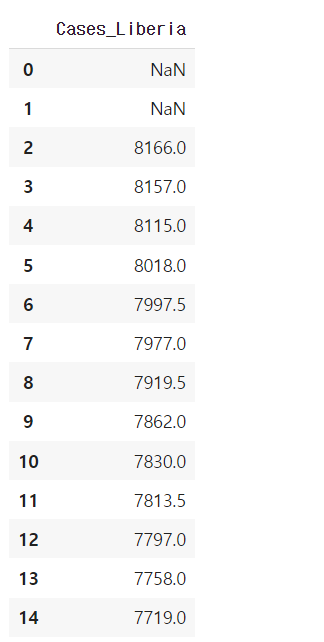
:위의 실행 결과에서 0과 1이 어떠한 상수 값으로 대체가 되지 않는 이유는 위아래 값이 불충분하기 때문
:원래 공백이었던 index 6번의 값과 8번의 값이 다른 이유는 6번은 5번과 7번의 평균값이, 8번은 7번과 9번의 평균 값이 NA 값 대신에 보간되어 대입되기 때문이다.
-그럼 왜 보간법을 사용하는가?
: 결측값이 데이터 상에 존재하게 되면, 그 데이터를 시각화하였을 때 아래와 같이 뚝 떨어진 값으로 시각화된다
ebola['Cases_Liberia'].plot()
:그렇다고 해서 fillna() 메소드를 사용하여 모두 같은 값으로 치환시켜 데이터를 채우게 된다면 전혀 데이터 변화의 경향을 반영하지 못한 값으로 데이터가 채워져 시각화를 하였을 때 다음과 같이 나타나게 된다.

: 따라서 보간법을 사용하여 데이터 변화의 경향성을 반영하여 시각화하는 방법을 고안해내게 된 것
-보간법에 대해서
ebola['Cases_Liberia'].interpolate(method='dfas').to_frame()
: interpolate() 메서드의 매개변수로 엉뚱한 값을 전달하게 되면 위와 같이 value에러가 발생하며 오류 메시지가 뜨게 된다.
: 즉, 메소드에 매개변수로서 전달이 될 수 있는 메소드의 종류는 ['linear', 'time', 'index', 'values', 'nearest', 'zero', 'slinear', 'quadratic', 'cubic', 'barycentric', 'krogh', 'spline', 'polynomial', 'from_derivatives', 'piecewise_polynomial', 'pchip', 'akima', 'cubicspline'] 로 한정된다.
-선형보간법) method를 'linear'로 지정 -> 직선 형태가 경향에 맞춰지게 형성하는 것, 1차원에서 두 점 사이의 거리로 해당 누락값을 대체하는 것
ebola['Cases_Liberia'].interpolate(method='linear').plot()
-선형보간법에서 slinear 메소드를 이용하면 1차, 2차, 3차 항을 높이면서 보간하게 되어서 조금 더 부드럽게 데이터의 경향을 잡아감, 최대한 기존의 경향에 맞춰가게 된다, 미분값
ebola['Cases_Liberia'].interpolate(method='slinear').plot()
:육안으로 보기에는 큰 차이가 없지만 실제로는 기울기와 곡선도가 많이 경향에 더 맞춰진 모습
- cubic 메소드 ) 선형 보간법이 1차 함수를 이용한 것, slinear 메소드가 2차 함수를 활용한 것이라면, cubic 메소드와 같은 경우에는 차수를 한 번 더 올려 3차 함수를 이용하는 삼차보간법이 된다. 3차 함수를 이용하여 미지의 값을 추정하게 되면 일차함수를 통해 찾는 것보다 훨씬 더 부드러운 결과를 만들어낼 수 있게 된다.
ebola['Cases_Liberia'].interpolate(method='cubic').plot()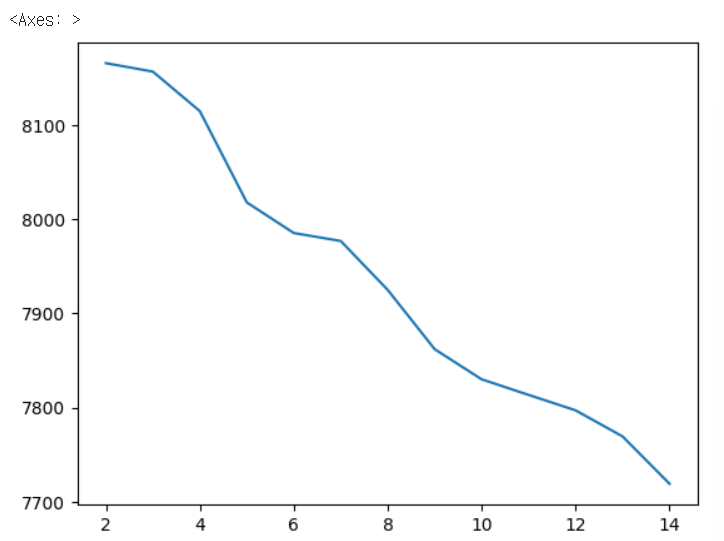
-spline 메소드 ) 기존에는 1차원의 표현으로 생각하여 보간을 하였다면, spline 통해 order의 차수를 높이면 2차원 이상으로 차원이 높아지게 하여 보간하는 방법
- time 메소드) 시계열 보간법
-어떤 형식을 취해서 보간할 지는 데이터의 측성을 고려하여 의사결정
코드 조금 바꿔서 해 본 복습 과제 제출물
'Data > 23_2 BDA 데이터 분석 기초' 카테고리의 다른 글
| [필수 과제 1] bike 데이터 보간법 (0) | 2023.09.24 |
|---|---|
| [2주차 복습] 데이터 전처리 기초 문법 (0) | 2023.09.17 |

